
How do we know what we know? That question is the subject of study for the field of epistemology. Per Wikipedia, “Epistemology studies the nature of knowledge, justification, and the rationality of belief.” Science is one powerful means to knowledge. Per the linked Wikipedia article, “Science is viewed as a refined, formalized, systematic, or institutionalized form of the pursuit and acquisition of empirical knowledge.”

Gathering Empirical Evidence
Most people are familiar with the basic scientific method: Pose a hypothesis about the world and then carry out an experiment whose empirical results can either support or falsify the hypothesis (and, inevitably, suggest additional hypotheses). In PL research we frequently rely on empirical evidence. Compiler optimizations, static and dynamic analyses, program synthesizers, testing tools, memory management algorithms, new language features, and other research developments each depend on some empirical evidence to demonstrate their effectiveness.
A key question for any experiment is: What is the standard of empirical evidence needed to adequately support the hypothesis?
This post is a summary of a paper co-authored by George T. Klees, Andrew Ruef, Benji Cooper, Shiyi Wei, and me that will appear in the Conference on Computer and Communications Security, this Fall, titled “Evaluating Fuzz Testing.”[ref]I also presented our work at the ISSISP’18 summer school, though the work has matured a bit since then.[/ref] It starts to answer the above question for research on fuzz testing (or simply, fuzzing), a process whose goal is to discover inputs that cause a program to crash. We studied empirical evaluations carried out by 32 research papers on fuzz testing. Looking critically at the evidence gathered by these papers, we find that no paper adheres to a sufficiently high standard of evidence to justify general claims of effectiveness (though some papers get close). We carry out our own experiments to illustrate why failure to meet the standard can produce misleading or incorrect conclusions.
Why have researchers systematically missed the mark here? I think the answer owes in part to the lack of an explicit standard of evidence. Our paper can be a starting point for such a standard for fuzz testing. More generally, several colleagues and I have been working on a checklist for empirical evaluations in PL/SE-style research. We welcome your feedback and participation!
What is Fuzz Testing?

Fuzzing
Fuzz testing is a process of repeatedly generating random inputs in an attempt to find one or more that cause a target program to fail, usually via a crash. Crashes due to segmentation faults and illegal instructions are signs of memory corruption, which usually arises from bugs that are potential vectors of attack. As such, finding and fixing crashing bugs is important for security.
Modern fuzz testing tools (“fuzzers”) generate new inputs by repeatedly and randomly mutating prior inputs, starting with one or more initial seeds. Which inputs to retain, and which mutations to apply, may depend on measurements gathered during the target program’s execution. A common measurement is the set of basic blocks that were executed. Inputs that execute new basic blocks are “interesting,” and so used as the start of future mutations.
Fuzz testing is effective and its use in industry in popular. Two well-known fuzzers used at Google are AFL and libfuzzer. Fuzz testing is also a popular topic for research. Several research tools exist, such as (in no particular order) AFLFast, T-Fuzz, VUzzer, and Driller. Over the last several years, fuzzing papers have regularly appeared in top security conferences.
Evaluating Fuzz Testing Evaluations
A good fuzz tester will find bugs in many programs, quickly. A research paper on a new fuzz testing algorithm (call it A) will attempt to show this by carrying out an empirical evaluation with the following elements:
- a compelling baseline fuzzer B to compare against;
- a sample of target programs—the benchmark suite;
- a performance metric to measure when A and B are run on the benchmark suite; ideally, this is the number of (possibly exploitable) bugs identified by crashing inputs;
- a meaningful set of configuration parameters, e.g., the seed file (or files) to start fuzzing with, and the timeout (i.e., the duration) of a fuzzing run.
An evaluation should also account for the fundamentally random nature of input generation, which means different runs could produce different results. As such, an evaluation should measure sufficiently many trials to sample the overall distribution that represents the fuzzer’s performance, using a statistical test to compare the performance of A and B.
We looked at 32 research papers written during the last five years, located by perusing top-conference proceedings and other quality venues. We studied their experimental evaluations and found that no fuzz testing evaluation carries out all of the above steps properly (though some get close).
This is bad news in theory, and after carrying out more than 50,000 CPU hours of experiments, we believe it is bad news in practice, too. Using AFLFast (as A) and AFL (as baseline B), we carried out a variety of tests of their performance. We chose AFLFast as it was a recent advance over the state of the art; it is based on AFL which is a common baseline in fuzzing research (14 of 32 papers we studied used it); AFLFast’s code was publicly available; and we were confident in our ability to rerun the experiments described by the authors in their own evaluation and expand these experiments by varying parameters that the original experimenters did not. We found that experiments that deviate from the above recipe could easily lead one to draw incorrect conclusions.
I will highlight some of our analysis and results in this post; for the rest you can look at the paper (or these slides, though they are slightly out of date).
Multiple Trials and Statistical Significance
Because fuzz testing is a random process, we can view each fuzzing run as a sample from a probability distribution. Simply put, each fuzzing run is like rolling a (very complicated, many-sided, possibly biased) die. Just as we cannot roll a die once to understand its tendencies (is it biased toward a particular numbers/sides, or is it fair?), we cannot run a fuzzer just once to assess its effectiveness at finding bugs. Running a fuzzer one time might involve a series of random choices that uncover 5 crashing inputs. Running it another time will involve different random choices that could uncover 10 crashes, or none.
And yet, what we found was that nearly 2/3 of the 32 papers we looked at did not report running fuzzers A and B more than once when assessing whether A was better than B. Of the papers that did report more than one run, the number of runs varied a fair bit. Only three papers described the measured variance of those multiple runs (e.g., as a standard deviation).
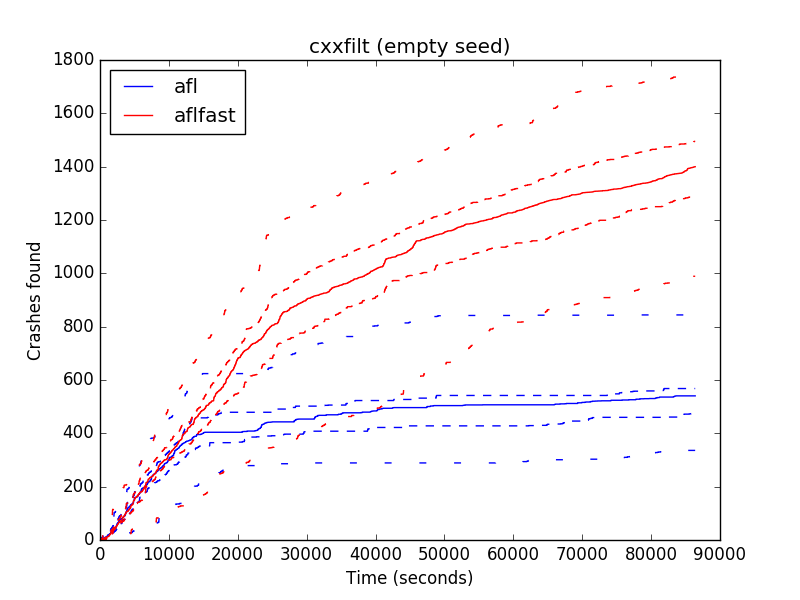
Crashes found over time, starting with the empty seed. Solid line is median; dashed lines are confidence intervals, and max/min. p-value < 10-10
Experiment.
Perhaps variance in fuzzing is low, and multiple runs are not necessary? According to our experiments with AFL and AFLFast, that need not be the case. The graph to the left plots the performance of AFL and AFLFast over time while fuzzing the program cxxfilt. The X-axis is seconds (totaling up to 24 hours) and the Y-axis counts the number of “unique crashes” found, which are crash-inducing inputs that AFL deems to be different from one another (more on this later). We ran each fuzzer 30 times. The solid lines represent the median, the inner dashed lines represent 95% confidence intervals, and the outermost dashed lines indicate the maximum and minimum.
Looking at the graph, we can see significant variance in performance. AFLFast finds anywhere from 800 to 1700 unique crashes and AFL finds between 350 and 800. Moreover, we see that the lines overlap: The minimum AFLFast line is below the maximum AFL line at the 12-hour mark. As such, even though the overall trend is in favor of AFLFast, an unlucky pair of measurements (stopping at 12 hours) might have led us to the opposite conclusion.
While it is good to look at the medians when assessing the overall trend, it may be that a higher median is still due to luck. The chances that a performance difference is not real are given by the p-value produced by a statistical test. A p-value of less than 0.05 is traditionally taken to be low enough that the trend is not due to chance. Following the advice of Arcuri and Briand, we use the Mann Whitney U test and find that for cxxfilt, sure enough, the p-value is 10-10, and thus the difference is very unlikely to be due to chance. However, other experiments (on other targets) we carried out yielded p-values greater than 0.05, indicating that an apparent difference in median performance may well be due to chance. No fuzzing paper of the 32 we looked at used a statistical test.
I have necessarily kept this discussion brief; please see the paper for more nuanced discussion and detail. The key takeaway is: We need to be carrying out multiple trials when assessing fuzzer performance, and we should be using statistical tests to compare the performance of a proposed fuzzing algorithm against that of the baseline.
Performance and Seeds
An important starting point for mutation-based fuzzers is the seed input. Conventional wisdom says a fuzzer performs better with small, valid seeds. These drive the program to execute more of its intended logic quickly, rather than cause it to terminate at its parsing/well-formedness tests. For example, if we are fuzzing a PDF viewer, conventional wisdom would indicate valid PDF files be used as seeds. Only 2 of 32 papers we looked at used an empty file as the seed. Of the rest, 10 said they used non-empty seeds, and 9 more specified the use of valid (non-empty) seeds, but none of these 19 papers said anything about the seeds themselves. It is as if they are assuming the particular seed does not matter.
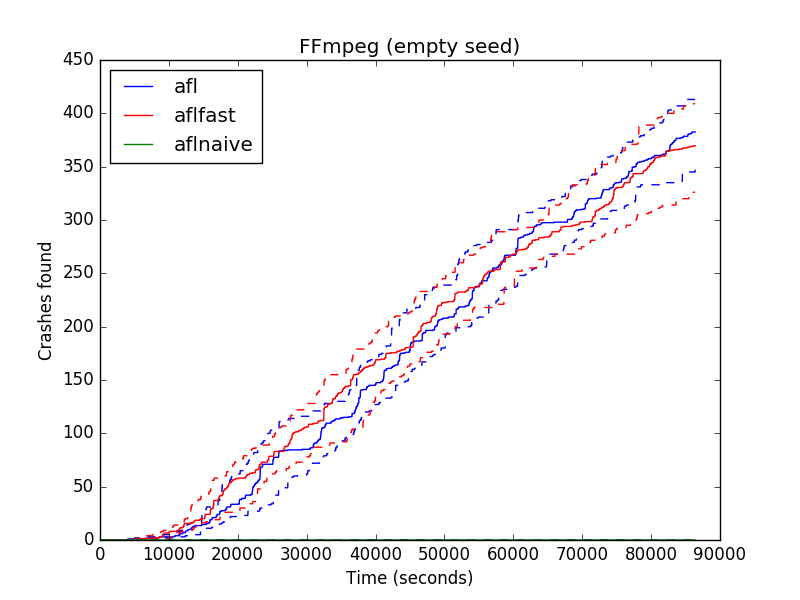
Crashes found with empty seed
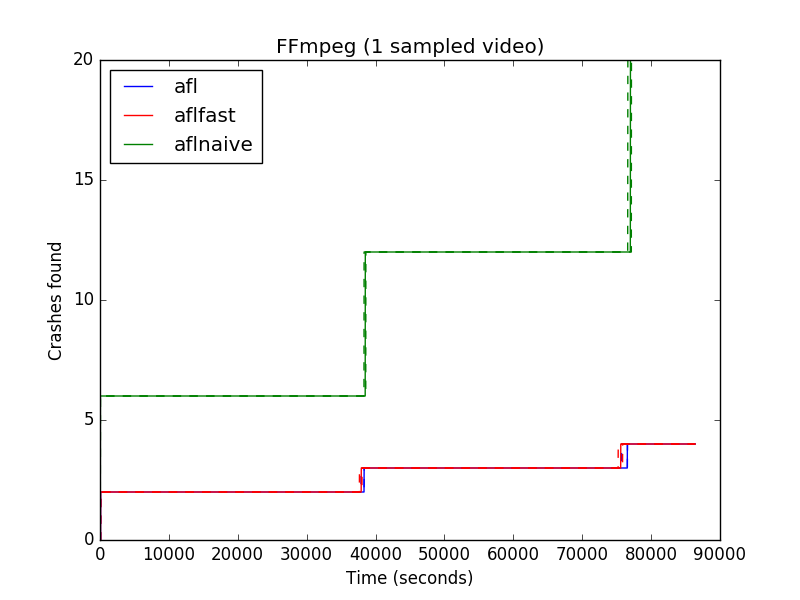
Crashes found with sample video as the seed
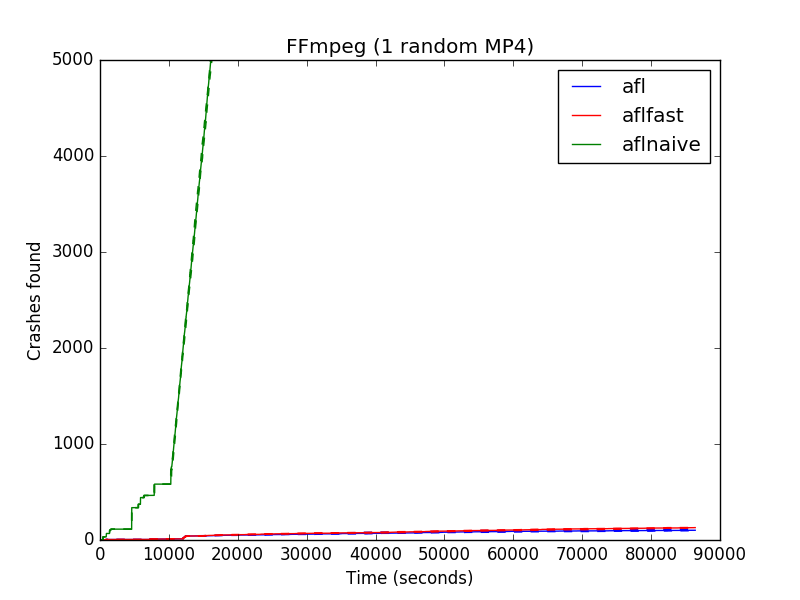
Crashes found with randomly constructed video as the seed
Experiment.
To test this assumption, we ran several experiments with varying seeds. The adjacent three graphs show the performance of AFL and AFLFast on FFmpeg, a program for working with streaming media (e.g., video and audio) files. The three graphs show the performance when setting the seed to an empty file, a sample video present on the FFmpeg web site, and a video constructed by stitching together random frames (respectively). As another point of comparison, we ran AFL in a mode that does not gather code coverage information while running, effectively making it a “black box” fuzzer. We call this version AFLnaive.
The clear takeaway is that the performance of the fuzzer can change dramatically when we change the seed. When using the empty seed, AFL and AFLFast find hundreds of crashes, but when using the sample and random seed, they find far fewer. Conversely, AFLnaive finds no crashes with the empty seed, but thousands of them with the randomly constructed one! The paper has additional data and experiments that show the same thing: Changing the seed can dramatically change performance.
Assuming that an evaluation is meant to show that fuzzer A is superior to fuzzer B in general, our results suggest that it might be prudent to consider a variety of seeds when evaluating an algorithm. Papers should be specific about how the seeds were collected, and better still to make available the actual seeds used. We also feel that the empty seed should be considered, despite its use contravening conventional wisdom. In a sense, it is the most general choice, since an empty file can serve as the input of any file-processing program. If a fuzzer does well with the empty seed across a variety of programs, perhaps it will also do well with the empty seed on programs not yet tested. And it takes a significant variable (i.e., which file to use as the seed) out of the vast configuration space.
Bugs vs. Crashes
The ultimate measure of a fuzzer’s success is the set of bugs (i.e., code defects) that it finds. But fuzzing papers often don’t measure “bugs found” directly. Rather, they measure “unique crashes” which we hope will correlate with bug counts, and are based on heuristics. Two common heuristics are AFL’s notion of “coverage profile” (used in 7 papers we looked at) and stack hashes (used in 7 others). A key question is: How good are these heuristics at approximating ground truth? If they dramatically over- or under-approximate the truth, then our empirical measurements could lead us astray.
Experiment.
To answer this question, we triaged the crashing inputs that were produced by AFL and AFLFast for cxxfilt. Using AFL’s notion of coverage profile, 57,142 “unique” inputs were generated across the 60 runs. To triage them, we systematically applied the code updates that have occurred since the two year-old version of cxxfilt that we fuzzed. Many of these updates fix bugs that were found by fuzzing. We know this because after applying an update and re-running the program, some fuzzer-discovered inputs no longer cause cxxfilt to crash. All those inputs that no longer crash after a particular update correspond to the bug fixed by that update. (We took steps to confirm that the fix is deterministic and to ensure that each update corresponded to a single bug, though this is not actually so straightforward.)
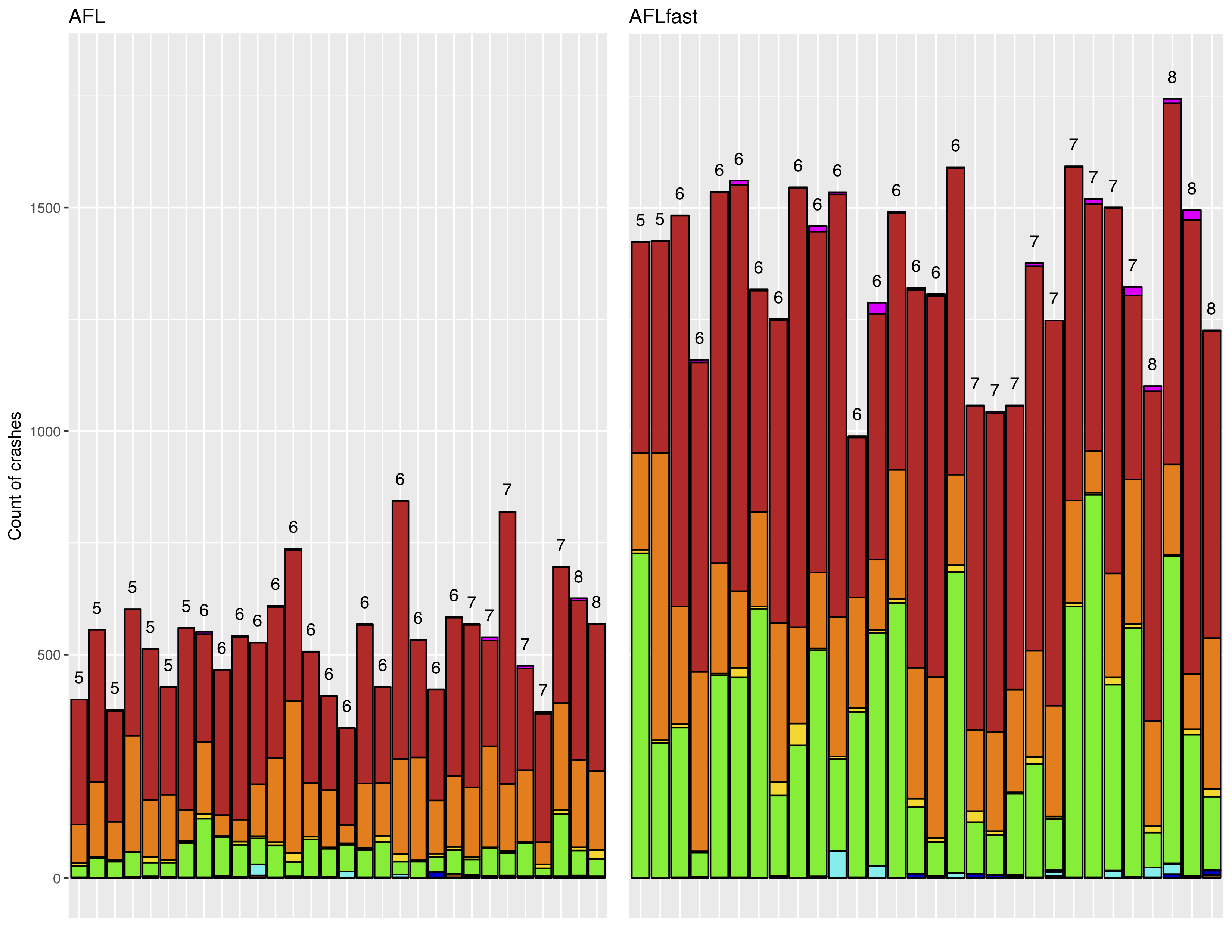
Grouping of crashes into actual bugs, for each fuzzing run. Actual bug counts at top of bars.
The result of this process identified only 9 distinct bug-fixing updates! Treating crashing inputs as bugs thus massively overestimates the effectiveness of the fuzzer. The figure above organizes these results. Each bar in the graph represents a 24-hour fuzzing trial carried out by either AFL or AFLFast. For each of these, the magnitude of the bar on the y axis is the total number of “unique” (according to coverage profile) crash-inducing inputs, while the bar is segmented by which of these inputs is grouped with a bug fix discovered by our ground truth analysis. Above each bar is the total number of bugs discovered by that run (which is the number of compartments in each bar). The runs are ordered by the number of unique bugs found in the run.
We can see that there is at best a weak correlation between the number of bugs found during a run and the number of crashing inputs found in a run. Such a correlation would imply a stronger upward trend of crash counts when moving left to right. We also see that some bugs were found repeatedly (red, orange, and green bars), while others were much harder to find. Indeed, no single run found all 9 bugs. So: Not all crashing inputs are “equal.” We can also see that AFLFast generally found many more “unique” crashing inputs than AFL but the number of bugs found per run is only slightly higher. Mann Whitney finds that the difference in crashes is statistically significant, with a p-value of 10−10, but the difference in bugs is not (but is close)—the p-value is 0.066. The paper contains much more discussion, and an assessment of stack hashes.
While this is just one experiment, it does call into question the use of bug heuristics when assessing fuzzing performance. A better practice is to evaluate using ground truth, either determined as we have done or by using a benchmark suite for which bugs are known. Examples of the latter are the Cyber Grand Challenge suite or LAVA-M (though these have their own problems). In general, the fuzzing community could really use a solid benchmark suite.
There’s more!

There’s more (danger) !
There is a lot more in the paper. There is more experimental data on the questions considered above. There is data and analysis on the questions of the efficacy of stack hashes and how long to run the fuzzer. We also pose open questions, and sketch steps toward their resolution. Most importantly, we look carefully at the choice of target programs used by fuzzing researchers and identify the path forward toward a more robust benchmark suite.
Why did this happen?
One question we don’t answer in our paper is, “Why do so many papers fail to follow the best practices?”
One possible answer is ignorance: The authors just didn’t know better. This may be true in some cases, e.g., that “unique crashes” are a pretty bad stand-in for “bugs”. But in other cases it rings false. It’s “science 101” to know that you need multiple samples of a non-deterministic/randomized process to understand expected behavior.
Another explanation is that there simply aren’t better alternatives than what was done. For example, there does not exist a great benchmark suite for fuzzing — that’s a work in progress.
I also think part of the issue is a combination of uncertain standards and incentives. Papers are accepted by the peer review system. This means that if three (or so) reviewers approve of the paper it’s published. Authors are evaluated by publishing, so they are incentivized to meet the bar set by the reviewers. The more (top) papers you publish, the more “successful” you are. So you are not incentivized to get far over the bar; just the other side of it suffices.
Failing to get over the bar
But the bar set by reviewers is not particularly sharp. Reviewers rate a paper based on whatever criteria they have in mind when they review it. If there is no clear, written, organized standard, reviewers may miss or underrate important flaws. For example, in terms of the presentation, reporting on an experiment with a single trial (bad!) is not much different than reporting on multiple trials. The latter may simply have an extra sentence saying, “We ran 11 trials and here report the median measurement.” It might also have graphs with error bars. These things are easy to miss. And yet, they are potentially crucial for believing the evidence supports the hypothesis. A reviewer, when asked explicitly, will agree that multiple trials are important. But that reviewer may forget to confirm that multiple trials were actually carried out, when reviewing the paper.
As such, I hope our paper can serve as a start toward that organized, written standard. The conclusions of the paper give explicit advice that can be adopted now. They also enumerate problems that require attention so as to improve the quality of evidence of future papers.
Guidelines for Empirical Evaluations
Motivated by what I was seeing in fuzzing, last year (while still SIGPLAN Chair) I formed a committee whose goal was to develop guidelines for carrying out empirical evaluations in PL research generally. This committee, comprised of Steve Blackburn (Chair), Emery Berger, Matthias Hauswirth, and myself, examined a sample of papers published in top PL venues. Based on what we saw, we developed an empirical evaluation checklist that organizes and categorizes elements of a good empirical evaluation. The hope is to assist researchers and reviewers by making a standard that is clear and actionable, as per the checklist manifesto. The advice we provide in Evaluating Fuzz Testing is an instance of the broader advice encapsulated in this checklist.
Science is one of the best sources of knowledge that we have, but only if we do it right. As scientists, we need to be vigilant to use the most appropriate methods, and to insist that others do the same. Only then can we start to feel confident that what we think we know is the truth.
Acknowledgments
Foremost, I must thank George Klees, Andrew Ruef, Benji Cooper, and Shiyi Wei for their contributions to the work reported here. I also thank Marcel Böhme and Abhik Roychoudhury for their help with AFLFast. I thank Michelle Mazurek, Cornelius Aschermann, Luis Pina, Jeff Foster, Ian Sweet, the participants of the ISSISP’18 summer school, and Mathias Payer for helpful comments and suggestions on the work, and on drafts of our paper.
Just a slight nitpick on understandability.
“Because fuzz testing is a random process, we can view each fuzzing run as a sample from a probability distribution.”
This sentence was confusing to me because I interpreted the term “fuzzing run” to be an individual sample (i.e. execution of the program under test) by the fuzzer.
The reason I like this work so much is that it’s very actionable. It clearly integrates nicely with the rebuttal system of major conferences. In particular, we hope that researchers begin to meet the proposed fuzzing standard. However, if they don’t, then it is easy for reviewers to mention this in their review. As you say, the correction for authors is at best a minor cosmetic change and at worst a (necessary) overhaul of their evaluation methodology.
Thanks, Ian!
Want to add another, unrelated point: Sam Tobin-Hochstadt, on Twitter, raised the issue of p-hacking (see https://projects.fivethirtyeight.com/p-hacking/), and wondered whether we should be recommending using p-values and statistical tests. He pointed to a paper by Gelman et al: https://andrewgelman.com/2017/09/26/abandon-statistical-significance/
I think this is a good point. I want to think more about it, but my current feeling is that abandoning methods for comparing two distributions is an extreme step. Perhaps we should not use the sharp p-value < 0.05 cutoff to deem a result worthy or not, but using no statistical comparison at all seems worse. I also wonder whether fuzzing is different than the social sciences (the context of Gelman et al's article). There, data is hard to come by and the systems being measured are extremely complicated and noisy (i.e., human behavior and societies). OTOH, fuzzing is relatively simple, and it's relatively easy to get more data. So there's less danger of p-hacking, and less excuse/need to do so.
Very cool — quite literally I just finished up some testing of similar sort as I have been thinking on this topic as well. I appreciate your recent slides as well. I am currently only using AFL and AFLFast as well. I had been using AFLGo too, but I wanted to first remove the variable related to code path affinity selection. My current testing is for analyzing how these perform against fuzzing roadblocks related to the input data(i.e., magic values, checksums, etc ). It is intended only to test these types of things in order to develop rules of thumb for different fuzzers on how much power to throw at a given code base (e.g. have a static analysis for this). I am hoping to include VUzzer and the new GATech work too soon enough.
Verry cool work. I see you use 30. I have seen that as a rule of thumb in other arenas, too. I see from some Evolutionary Algorithm analysts that they do 30 for general idea and 100 if going for paper (per Randal Olson’s “A short guide to using statistics in Evolutionary Computation”). What do you think?
Regarding duration / timeout, this has been plaguing me too… Half thinking of timeout half thinking of using Pythia’s method (see Bohme STADS work).
I see Emery Berger on that panel; I am in the uni-town he is a prof at… any chance you will be at UMass this year?
Thanks! To your questions: We chose 30 because Arcuri and Briand mentioned that number. However, any number of trials is fine, some sense — more trials will get you a better (lower) p-value. As for timeout, we also considered survival analysis, which aims to predict “survival” even if beyond the observed period. But adapting that to a numeric bug count, and a trend that seems fairly hard to predict, seemed contorted, so we just looked at particular periods. As for going to UMass: No plans at present, but you never know! Emery is a great person to talk to about this sort of thing. And, he’s familiar with this work as he was in the room when I presented the slides.
Thanks for the response! It is a good topic and needs this type of movement toward rigor / getting our collective story straight, in my humble opinion.
Very nice work — I appreciate your bringing this up and has been on my mind for awhile, as well. I appreciated your other slides, as well.
Coincidentally, I have been running some tests of my own in this realm. I am mostly looking at how different fuzzers deal with “fuzzing roadblocks” such as input data that has a checksum field — so only looking at the ability to get to a certain branch after such a calculation and compare based on the input data. So these test code have low branch counts with the aim to just test these cmp/br. Or combinations of these, as in first it checks a magic and then it checks a checksum. My thinking on this is possibly stupid, but I am interested in the “local” behavior so as to think about creating rules of thumb for different fuzzers to estimate how much power to throw at a fuzzing campaign (via some static analysis of the code base). Also I am interested in getting the numbers to these simply to think about local vs global analysis of fuzzers (where I think of global analysis as number of bugs found type statistics). Any opinions on this are welcome and I will share results if interested? (maybe I can just put on on a web page and email you).
Funny enough, so far I have only done my tests with AFL and AFLFast. I am using timeouts (which I am still wondering about :-/). I am using seeds that have “good values” — e.g. a good checksum, or the right magic field value for the code to reach the desired branch. I am also using seeds in separate runs with bad values — e.g, bad checksum or invalid magic value so it exits prior to my desired branch I want the code to reach. I have preliminary data, but I am working up to 30 runs.
I had included AFLGo prior, but wanted to reduce variables in comparison and so took it out to avoid path affinity selection. I will include VUzzer, Driller, and the new GATech work soon.
Back to duration of fuzz: I wonder if there is something to using Boehme’s STADS work. So you have 2 different tests you perform: a timeout based set of runs and then a set of runs that are “killed off” after they reach the criterion discussed in STADS paper. This way, there is a compare/contrast perhaps? Im not sure.
Along the line of 30 runs, I was reading [1] and they were suggesting 30 for a “good sense” and 100 if you’re submitting a paper. I have heard 30 from other fields, as well. Any thoughts on the 100 number?
Any chance you will come to UMass at all this year per committee colleague being a prof here?
[1] http://www.randalolson.com/2013/07/20/a-short-guide-to-using-statistics-in-evolutionary-computation/
An aside: I have been thinking of analyzing runs of a fuzzer (i.e, one of the 30 fuzzer runs) as an evaluation of some function f upon some targeted input/source. That is, in the evaluation of f, there are many executions of the targeted program with varying inputs. Since a fuzzing takes time, plus whatever other resources, we can consider that evaluation of f is expensive/costly. I sort of am pondering if there is something from Bayesian Global Optimization to apply from that perspective .. but, right, that was a random aside.
Thanks for this, it is most illuminating.
On the subject of distinctness of bugs, I think this is particularly hard for the type of issue found by fuzzing: since they are usually by definition crashing bugs, it appears to be quite common that they are caused by a corruption induced at one point that causes a crash only later; as a result, minor details of input that do not change when and how the corruption is induced can easily change the path followed after that point, and the resulting stacktrace.
I’ve triaged many issues reported from fuzzing against the perl project, and from that experience have commonly found that two inputs could be determined to be triggering the same bug only after a full root cause analysis (which requires much more familiarity with the codebase than is needed to run a fuzzing tool).
Of course that may not be a problem if you have a corpus of known bugs, and a way to link an input to one or other of them.
I agree that triage is a non-trivial effort, best left to the target program’s maintainers. That’s why we suggest using programs with known (but realistic) bugs when comparing tools. Developing a good benchmark comprising such programs is an open problem, though there are good (if not perfect) options out there.
Pingback: Evaluating Empirical Evaluations (for Fuzz Testing) | SIGPLAN Blog