
I did my PhD on a topic I called dynamic software updating (DSU), a process by which a running application is updated with new functionality, whether to add features or fix bugs, without shutting it down. As a faculty member, I supervised several PhD students on DSU projects. These considered the semantics of DSU and ways of reasoning about and/or testing a dynamic update’s correctness (including while it’s deployed), and ways of implementing DSU, using compilation, libraries, and/or code rewriting. All of this work resulted in what are, as far as I’m aware, still the most full-featured and efficient implementations of DSU for C and Java, to date.
While DSU handles the update of long-running, single-process applications, many long-running applications also involve a database management system (DBMS) to store persistent application data. For example, an online market will have a front end to present the user interface, but the market’s inventory, purchase log, user reviews, etc. will be stored in the back-end database. As such, a single logical change to an application could well involve individual changes to both the front-end code and the contents and format of the database. Maybe our upgraded market now provides access to an item’s price history, which is implemented by extending the DB schema and by adding front-end functionality to query/access this information. To realize this upgrade dynamically, we need to change the application and the database, in one logical step.
In a paper presented at SIGMOD this month, we describe Bullfrog, a new DBMS that supports online schema updates in a way that enables whole-application upgrades. An application change can be applied by DSU for the front-end instances and by Bullfrog for the back-end DB. A key feature of Bullfrog is that on the one hand, the schema change is immediate, which simplifies front-end/back-end coordination of the update, especially when schema changes are backward incompatible. On the other hand, data migration to the new schema is lazy, as the application demands it. Lazy migration avoids a potentially lengthy update-time pause, which would result in loss of availability, defeating the
whole point of DSU. There were lots of challenges to realizing the lazy updating model. I give a flavor of the approach here; the paper has the details.
This work was co-directed by my colleague Daniel Abadi and myself, and carried out by Souvik Bhattacherjee and Gang Liao (each making equal contributions). All code, which extends PostgreSQL, is available online.
The Crux of DSU: The Changing State
When you first hear about DSU, you think about replacing the code while it runs. How should we do that? This is actually not hard. Indeed, if all you care about is the code, then you can just shut down and restart the process. What you really care about is the state of the running process, which is what you’d lose if you shut the process down. In-flight connections would be dropped, and any in-memory storage would disappear. For example, consider the redis key-value store, which keeps all relevant storage in memory. If you simply killed the redis process and then started its new version you would cancel existing client sessions and you would drop all of the data kept in the store.
One workaround to these problems is to design the application to checkpoint its state to disk (e.g., the data in the key-value store) and/or the OS (e.g., the open connections) prior to an update, and then restore that state after the new version restarts. But this begs the question: What if the upgrade to the application changes the way the state is represented, e.g., to fix bugs or support new features? The new version of the application might expect the checkpointed state to be in a different format, and thus a transformation function is needed to map that old format to one expected by the new version.
In essence, this is what single-process DSU does, minus the checkpoint, stop, and restore: It upgrades the code in place, thus retaining OS-level process state (like connections), and then modifies the in-memory application state by transforming it to conform to the new code’s expectations. Doing so is faster than to-disk checkpoint and restart. Moreover, by transforming state on demand, rather than all at once, we can reduce the update-time pause to a modest, temporary overhead on post-update transaction latencies.
While checkpoint and restart may not be the best approach for single-process DSU, it suggests how we might update an application with both a front-end and DB component. In particular, we can view a DB state change the same way we think about a change to a process’s in-memory state: If the DB state format, i.e., its schema, changes then we need a specification and mechanism to transform, aka migrate, the existing data to match the new schema (which the new front-end version will expect). A key challenge is how to do this migration efficiently.
Lazy, On-line Schema Migration
Bullfrog is our solution to this problem, commonly referred to as the online schema migration problem. While existing DBMSs do support some online schema changes, not all desirable changes are supported. An update is specified to Bullfrog as a new schema, along with a schema migration transaction that specifies how the new schema elements’ data should be initialized based on the current contents of the database (which conform to the old schema). Upon receiving this information, Bullfrog takes two steps. First, it creates any needed tables, which are empty. Second, it uses the migration transaction to set up a view between the old tables and the new ones, basically expressing the transformation function from old to new.
At this point Bullfrog carries out a logical flip to the new version, which requires that the front-end be updated too, using DSU if it contains useful/important state. If old-version transactions come in after the flip, Bullfrog can abort them and signal the issuing front-end to update itself.
After the flip, Bullfrog processes incoming transactions in two steps: First, it migrates tuples from the old tables to the new ones needed to service the query. Second, it processes the query on the new tables. In other words, Bullfrog migrates old-version data lazily, as the front end processing demands it. Doing so has the benefit that a long pause at update time is avoided; that pause is instead amortized over subsequent processing.
To migrate data lazily, Bullfrog translates the new-version query via the established view and retains any WHERE clauses in the query, copying the identified data to the new tables. The WHERE clauses limit copied data to that which is needed for this query, and hopefully not much more. Data copying from old to new tables is itself transactional, since many queries will be happening at once. Bullfrog uses several novel algorithms to ensure that data is copied efficiently, and exactly once, despite parallelism and aborts. After a time, Bullfrog may spawn one or more background threads to migrate data not yet demanded by application instances, to make sure all data is eventually migrated.
The paper has many more details, if you are curious.
Experiments
To evaluate what Bullfrog can do, we developed a version of the standard TPC-C benchmark but with schema migration events within it and measured performance (utilizing 8 cores for parallelism) before, during, and after a schema migration is initiated. The paper has lots of experiments, with different kinds of schema updates, but for this post, I’m going to show just one, which involves an update that splits one table into two.
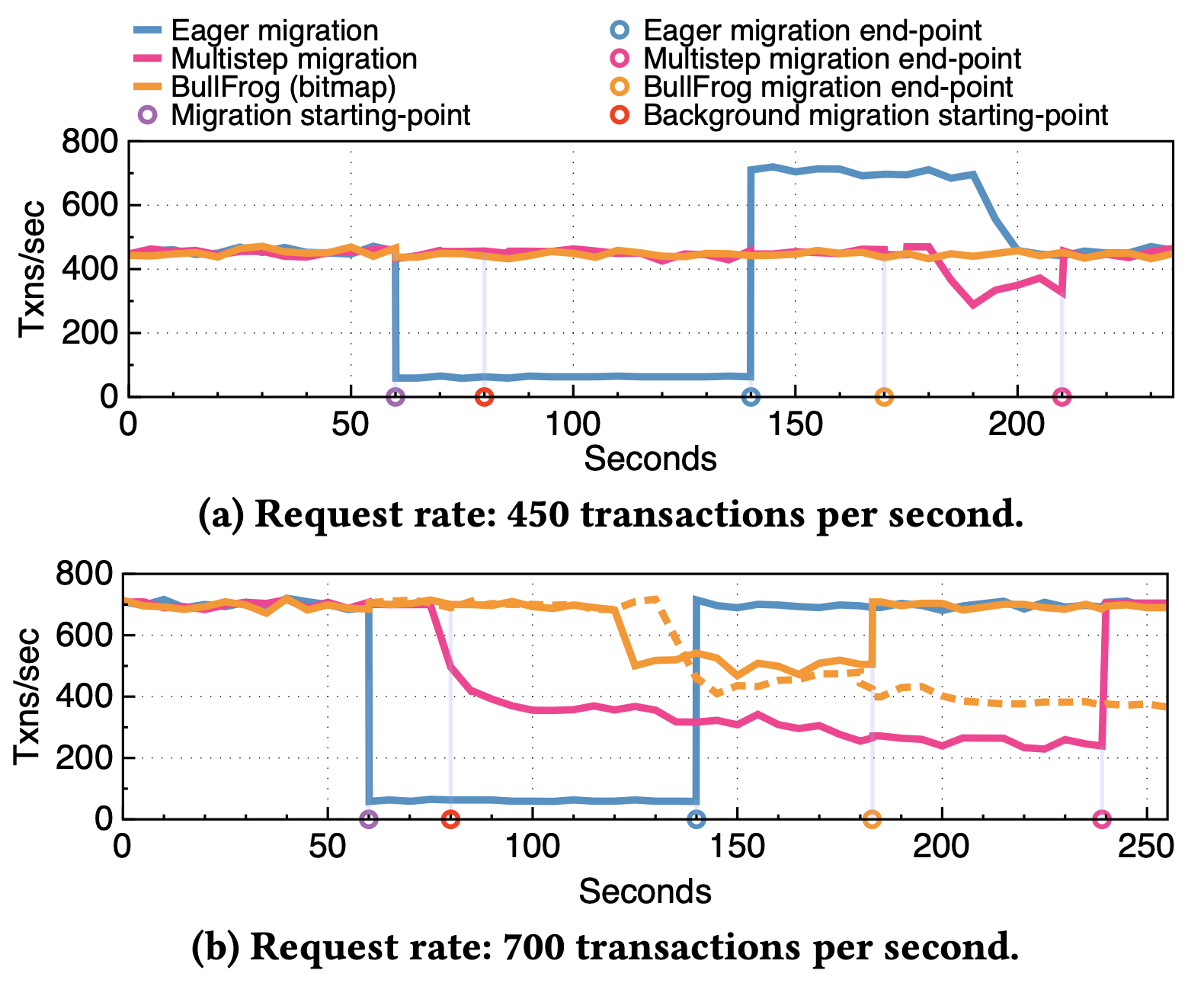
Comparing the transaction throughput of Bullfrog against alternatives, before, during, and after schema migration (DBMS throughput saturates at 700 TPS)
The figure shows a timeline along the x-axis and transaction throughout on the y-axis. Part (a) of the figure shows the situation when the benchmark issues transactions at 450 per second, while part (b) shows 700 transactions per second. The schema change is submitted at time 60. Each line in the graph represents a different updating strategy:
- The blue line is “eager” migration: When the update comes in, all transactions to updated tables are blocked until the data is migrated. In both part (a) and (b) the result is a sharp drop in throughput. In part (a), throughput bumps up after the migration is complete to service the queued transactions, but in part (b) the database capacity is at its max already, so DBMS never catches up.
- The yellow-orange line is Bullfrog’s best lazy strategy: For part (a) you can see that there is no loss in throughput during the update. In part (b) the overhead of lazy migration eventually saps throughput, but not nearly to the level as the eager approach. Moreover, we can see that the background threads are important for completing the transaction as quickly as possible, thus restoring the best-case throughput. (The green line is an alternative strategy for Bullfrog that I won’t talk about.)
- The magenta line is a “multi-step” update strategy, which simulates one employed by database systems today. In such a strategy, the new schema version is deployed in a new DBMS, and data is copied from the old DBMS to the new one in the background. Assuming the update is backward compatible, reads go to the old version, and writes go to both the old and new versions, for data present in both. The flip happens when the background process completes. We simulate this approach in our experiment by prepopulating the database with the new tables, and initiating a background copy. What we see is that the multistep approach finishes later than the lazy approach, since it ends up copying more data (writes go to both versions). Moreover, in the 700 TPS experiment, throughput steadily decays as the amount of double-written data increases.
Next Steps
I’m really proud of the work we have done on Bullfrog, and especially the fantastic work done by Souvik and Gang to build the system itself. I think it provides an important piece of the puzzle of how to ensure a service has very high up-time while also evolving to serve client needs.
There is more still to do. First, not all kinds of schema updates you might like can be serviced lazily, right now. More work needs to be done to support them. Second, while we designed Bullfrog to be part of an overall multi-tier application updating strategy, we have not completed a framework for applications specifically (our prior work on dynamic updating of NoSQL database data can point the way here). If you are interested in helping, get in touch!
Acknowledgments: Thanks to Daniel Abadi and Luis Pina for helpful comments on a draft of this post.
Really neat work!
Side-note: Your link to Kitsune doesn’t seem to work anymore, and neither does Kitsune’s website linked from the GitHub organization (http://kitsune-dsu.com/). Any idea what happened to that?
Thanks for pointing this out. The student who set this up has left and we are trying to get control back. Stay tuned!
Couple of lessons learned from production use of this pattern: 1. migration is more expensive than steady state (cpu, memory, i/o both disk and network). Once you initiate the migration your hottest data (users in our case) will all initiate migration at the same time. In our case, it caused an outage as the service was not able to shed load. To fix this you want to lazy migrate but throttle load, for instance, by sample what is being migrated and what uses the old code code path. 2. After a brief period of time, a large percentage of the active data is migrated (say, 20%). This leaves 80% of cold data that you need to force migrate via a back-ground job. 3. In practice, you want more than 2 concurrent migration so you don’t block progress. I have yet to read the paper, so you may already have covered this.
Great points! If I am not misaken, we actually do all of the things you say, but perhaps not with the exact percentages/breakdown. I encourage you to check out the paper to see if you have followup thoughts.
Great stuff!