
Buggy software doesn’t work. According to wikipedia:
A software bug is an error … in a computer program or system that causes it to produce an incorrect or unexpected result, or to behave in unintended ways. Most bugs arise from mistakes and errors made by people in either a program’s source code or its design ...
When something is wrong with a program, we rarely hear of it having one bug — we hear of it having many bugs. I’m wondering: Where does one bug end and the next bug begin?
To answer this question, we need an operational definition of a bug, not the indirect notion present in the Wikipedia quote.[ref]Andreas Zeller, in his book Why Programs Fail, prefers the term defect to bug since the latter term is sometimes used to refer to erroneous behavior, rather than erroneous code. I stick with the term bug, in this post, and use it to mean the problematic code (only).[/ref]
This post starts to explore such a definition, but I’m not satisfied with it yet — I’m hoping you will provide your thoughts in the comments to move it forward.
Motivating scenario
My interest in distinguishing one bug from the next started with our build-it, break-it, fix-it (BIBIFI) programming contest. In the contest’s first round, builder teams write what they hope will be high quality software. In the second round, breaker teams look for bugs, including security bugs, in builders’ software. If they find a bug, they submit a test case that demonstrates it: The test case should succeed when run on our canonical “oracle” implementation, but fail on the buggy implementation. Builders lose points for each bug found, and while breakers gain points.[ref]Read more about the contest in this post.[/ref]
There’s one problem here: Failing test cases are evidence of bugs, but not on a one-to-one basis, since several test cases may tickle the same bug. For example, if I wrote a sorting function that fails to sort the last element of a provided list (e.g., perhaps due to an off-by-one error in the iterator), then the test that takes in=[2,1] produces out=[2,1] (when the output should be [1,2]). Another test revealing the same bug takes in=[4,3,2] produces out=[3,4,2] (when the output should be [2,3,4]). Many others tests, too, can serve as evidence of the bug. Therefore we cannot fairly equate a test case with a bug as that would over-penalize builders and over-reward breakers.
To solve this problem, I’d love some clear-cut method to determine that the two test cases are “the same” in that they are evidence of the same bug. Even if I can’t get a computer to do it, clear guidelines for humans would also be great.
But to do this I need to come up with a definition of “bug” that allows me to distinguish one bug from another.
The BIBIFI contest is not the only context in which you’d like to identify equivalent test cases. A fuzz testing tool (like AFL or CSmith) will generate many tests — we might like to weed out duplicate tests to minimize the number of bug reports, to increase the chances they are acted upon.[ref]One way to identify test cases that are evidence of the same bug is to minimize those tests, using something like delta-debugging or C-reduce, and then see if any are structurally identical. I posit that this might work for simple tests but will not work in general.[/ref] A bug bounty program (like Google’s) must determine when two submitted reports/tests identify the same bug, to reward only one submitter.
Towards a formal definition of bug
Here’s an attempt to state formally what a bug is, for the purposes of providing some insight into the question of how to distinguish bugs.
A bug is a code fragment (or lack thereof) that contributes to one or more failures. By “contributes to”, we mean that the buggy code fragment is executed (or should have been, but was missing) when the failure happens. A failure is an incorrect input/output pair (e.g., generated by a test case).
Example: Recall the sorting function that fails to sort the last element of the provided list because the iterator has an off-by-one error (on the looping condition); this bug induces the failures listed above (in=[2,1], out=[2,1], and in=[4,3,2], out=[3,4,2]).
A failure could be due to multiple bugs. This basically gets back to the main point of the post: An incorrect program might have many bugs, not just one.
Example: Suppose our sorting program has a printing routine that drops the first element of the list, when printed. Combined with the sorting off-by-one bug, we would have the failures in=[3,1,2], out=[3,2] and in=[1,3,2], out=[3,2]. (That is, we sort the first two elements of the list, leaving the third alone, and the print only the last two.)
Sometimes, the presence of one bug affects the failures or another, in which case we say the one bug interacts with the other bug.
Example: The printing bug interacts with the sorting bug, because its presence affects all failures due to (only) the sorting bug. For example, in=[4,3,2], out=[3,4,2] is masked; rather, in=[4,3,2], out=[4,2] is present, which is also wrong, but different. Conversely, the presence of the sorting bug hides some of the failures of the printing bug. For example, in=[4,4], out=[4] is a failure that is still present, but in=[5,4], out=[5] is not.
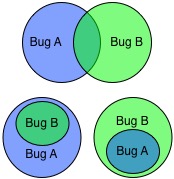
Interacting bugs
We can visualize this interaction with a Venn diagram depicting sets of failures owing to a particular bug. When bugs’ sets of failures overlap, then those bugs interact.
Non-interacting bugs
On the other hand, a bug does not interact with another bug when the failures due to the one bug are not affected by the other bug, and vice versa. In this case, the bugs’ sets of failures are non-overlapping.
A fix for a bug is a change to the problematic fragment (or is the addition of the missing fragment) that corrects the bug’s failures. However, when there are multiple bugs that interact, it may be hard to see that a fix to a single bug is efficacious, depending on the order that fixes are applied.
Example: If we first fixed the printing bug, then the failure in=[4,4], out=[4] would go away (yielding correct behavior in=[4,4], out=[4,4]), but we would still have the failure in=[4,3,2], out=[3,4,2] until we fixed the sorting bug. On the other hand, if we fixed the sorting bug first, the existence of the printing bug would still mask the improved behavior, i.e., all of our sorting test cases would still fail. That said, the failures would be different, and more illuminating about the reason for the remaining bug.
Criteria for separating bugs
Supposing that a bug is defined by wrong or missing code that results in a set of failures (i.e., test cases involving wrong input/output pairs), we still must determine which code/failures belong to one bug and which belong to another. This is where things get murky.
Fixes reveal bugs?
We might imagine that a fix could serve as evidence that multiple failures, produced by different test cases, are due to the same bug. In particular, if a single fix makes many failing test cases pass, perhaps that means these test cases should be viewed as due to the same bug?
Unfortunately, this argument is circular. It assumes that a fix applies to only one bug; but why should we assume it does? The code change could have fixed multiple bugs at once, meaning the test cases are not, in fact, the same. So this just kicks the can down the road: To determine if a fix covers multiple bugs, we need a definition of a bug that allows us to distinguish one bug from another.
Bug distinctions by code or specification granularity
I believe one important idea for defining bugs is to identify a level of granularity that serves as a frame of reference. Since bugs are in code, the level might be a code unit, like a procedure, or group of units, like a procedure and all of the procedures it calls. Another kind of granularity is not at the level of code units, but rather at the level of fragments of the specification.
Example: I could have implemented sorting as an insertion sort, with a sort routine and a insert subroutine. A bug in sorting might be viewed as a bug of insert, or a bug in the sort function; the choice might matter if there are several fragments of incorrect code in sort, in which case we might lump them all together as a single bug, or not. On the other hand, the specification of sorting might be the output array is a permutation of the input array, and the output array is ordered. It’s possible that a bug could fall into one half of this spec, or both. If the latter, then even if all of the code is in one unit (e.g., a single sort function) we might say there are two bugs. (Note that our sorting bug example — missing the last element — falls into the latter half of the above spec.)
Of course, code and spec units are somewhat arbitrary: We could write a program as one big function, perhaps with substantial redundancy, or we could write it as many smaller functions. Logical specifications could also be tight or redundant. Nevertheless, I think there is some “essence” of functionality that defines the boundaries of a bug, even if these boundaries might be a fuzzy, and depend on the beholder’s perspective.
Bug interactions complicate the situation because the visible outcome is due to multiple bugs, not one. Therefore it’s hard to tease apart the contributions of each bug. On the other hand, we can confidently say we have two different bugs if they do not interact. Even if the failures do interact, it may be that a potential bug has some non-interacting failures — i.e., its set of failures overlaps with those of another bug, but the set does not contain those failures and is not contained by it. As such, if we fix just that bug, at least these failures would go away, while the dependent failures would go away after fixing the other bug(s).
Bug characteristics
Bugs could be identified by some other element of their character, as opposed to related code or specification units. For example, there are different categories of coding mistakes, such as race conditions, off-by-one errors, div-by-zero, infinite loops, buffer overflows, etc. Even if something like a race condition involves code fragments throughout the program, we probably would consider the race a single bug, and therefore fix all of those fragments at once.
Conclusions and Questions
At this point in my thinking, what constitutes a single bug seems to be a subjective judgment whose basis roughly corresponds to program “features” as defined by distinct portions of code or the specification, or features of the coding error.
If you disagree, or see important subtleties that I have missed, please comment!
If I am right, then one question is how to nevertheless develop automated techniques for bug localization or bug triage given sets of failing and passing tests. For example, we might like to develop techniques that
- Cluster failing tests into groups that correspond to distinct bugs.
- Given a fix and a set of failing tests, determine whether the fix covers a single bug, or multiple bugs (which is another way of clustering the test cases).
What semantic information would be required for such computations? Traces of execution? AST-level diffs between the buggy and fixed versions?
Another question is how empirical analysis might help us refine the definition of a bug. For example, if we analyzed issue reports and resolutions (bugfixes) on Github, what would we find? Would most fixes be localized into a single code unit, supporting the idea that a bug tends to be local to a particular code unit? How often would we see duplicate or overlapping bug reports, suggesting that an initial report really involved multiple bugs, and not a single bug?
This exploration has been very interesting to me — I never would have thought that an idea as pervasive and well-known as “software bug” would be so hard to pin down!
Thanks to Alex Gyori, Piotr Mardziel, and Nikhil Swamy for interesting discussions on this topic and comments on drafts of this post.
Here’s an outline of a method to cluster bugs. Clearly our buggy program P0 is relative to some specification S0. Suppose that P0 can be decomposed into a context (with a hole) C0 and a sub-program P1, such that C0 satisfies specification [S1] => S0 (i.e., when plugged with sub-programs P1′ satisfying a sub-specification S1, C0[P1′] would satisfy S0). Then we have “reduced” the problem to dealing with a buggy P1 relative to S1. Hopefully this process terminates in simple buggy (sub-)programs obviously violating some simple (sub-)specifications.
The process of decomposing a buggy program is obviously the hard part here. But program analysis deals with such things (techniques like slicing, CEGAR, and so on come to mind as possibly related).
Very interesting! Some observations:
– This approach seems to think of bugs as localized code fragments (e.g., our off-by-one error), so that they can fill the context’s hole (assuming we are using the standard sort of definition of a context C). This approach jives with my view of a bug as being localized to a code unit, but that may rule out bugs like race conditions, whose fixes may be non-local.
– Assuming we can produce these specification fragments, S1 and S0, the reduction procedure seems to require that we can “run” C0[S1] to see that the result satisfies S0. To do this, we have to use S1 as a kind of executable specification, albeit a possibly non-algorithmic one. Then might even try to synthesize P1′ from S1 using perhaps other hints? If we do not have [S1] => S0, then the problem seems harder still?
If you use “bug” to refer exclusively to erroneous code, then the BIBIFI breaker teams aren’t actually finding bugs at all. All they have to do is demonstrate erroneous behaviour alongside an oracle implementation. (On the other hand, if the breakers have to identify the code segments that cause this behaviour, then the “fix it” round would be much less of a challenge…)
I like Zeller’s idea of emphasizing the distinction between buggy code (“defects”) and buggy behaviour (“bugs”). Defects clearly deserve higher status. (There’s a medical analogy here — an inherited disorder caused by a single genetic defect can manifest itself in a wide range of symptoms, but identifying the location of this defect can take years of study.)
Anyway, I’m looking forward to taking part in the next round of BIBIFI later this month 🙂
I agree that breakers are finding failures (my term, and Zeller’s too IIRC), i.e., erroneous behavior. The problem for the scoring procedure is knowing which failures are due the same bug, so that test cases revealing those failures are not over-weighted.
Glad you are looking forward to the contest — me too!
Sometimes trying to formalize a word from folk knowledge reveals that it actually doesn’t have any objective or useful meaning. Could “bug” be one of those?
I personally expect that, in the next few decades, we’ll come to look upon the concept (at least as related to the examples from this post) as archaic, like terms from medieval medicine, because formal methods and correct-by-construction techniques remove the possibility of not noticing deviations from specs. Talking about bugs in this way will seem like wasting time on a taxonomy of parse errors! Spec bugs are another story, but I think the dynamics there are fundamentally different from the ones explored here.
That’s a very interesting point! I guess in your world of correct-by-construction, the concept is really “inconsistency” between the spec and the code you intend to implement that spec. In that case, the code/spec is “buggy” until it is consistent, and whether there is one “bug” or several is not so material — you can do nothing with the code until it is consistent. But even here, it would seem that you might consider inconsistencies from one code unit as distinct from those in another.
I think the notion of a “bug” makes most sense with respect to a specification. When running a program, I would say a bug occurs *at the point when the program state first becomes invalid*.
To give an example, an image processing function might require a buffer size that is a multiple of four if the pixel format is “RGBA”. If this precondition is violated, a buffer overflow occurs. However, the bug is not where the overflow happens. I would say that the bug is in the part of the code that reads the input image. The postcondition of this part should state that the image is valid. This places the bug somewhere between the point where both the size and pixel format have been read, and the point where the final image is returned.
This is also where the input validity checks should go… but there are probably several such checks, and they can be in arbitrary order. So the location of the bug is not very precisely defined because the specification does not specify what happens inside the input reading function. It only says that at the end of the function, there must be a valid image.
Your definition agrees with Zeller’s definition, I think.
The question to me is how to tell whether there is a single issue that leads to the busted state, or many issues. For example, maybe your postcondition is that the image should be a certain size and that it should be black and white. Code that fails to ensure this condition might lead to problems later. Does the code have one bug or two? My “granularity” idea of specifications suggests the code might have two bugs, justified by the intuition that size and color requirements are separate clauses of the specification.
Maybe you could think in terms of disjunctions or conjunctions in the specification. In my example, it is the logical AND of two conditions that is violated. This happens at a specific point in time, and I would argue it’s a single bug.
In your example, two individual clauses of the specification are violated independently. The first bug occurs when the first of these clauses becomes unsatisfied. Once this happens, the specification as a whole is unsatisfied. This is binary; a formula can be true and false, not “slightly false” or “more false”. Yet my definition is still partially useful, because it identifies the location of the first bug.
Michael, great post! Precisely defining a “bug” is hard. I published a paper covering similar ground (“Counting Bugs is Harder Than You Think,” SCAM 2011, Paul E. Black. DOI: 10.1109/SCAM.2011.24), but ended up in very different places. It largely ignored failures (behaviors) and went straight to code. Sadly, considering (solely) the code didn’t resolve much.
I can report that most bugs are complicated. That is, the simple bug of a fragment of code at a specific location causing a distinct failure is the exception, not the rule. Typically a bug has interactions with other bugs or is effectively the interaction of code in many places or has a cascade of faulty states (e.g. a chain in which an integer overflow leads to a destination buffer too small which leads to a buffer overflow which leads to arbitrary code execution) or might even be argued to not be a bug!
We have tracked down the source code changes corresponding to several hundred CVEs. We have not thought to ask your questions at the end, about whether fixes are localized or whether many bugs (or failures) are involved.
== Bug distinctions by code or specification granularity ==
A programmer might have one conceptual flaw (say, not knowing to clear a resource after use) that is manifest as several buggy code fragments causing distinct failures. I could argue that the problem in the programmer’s mental model is just one … uh, bug from a certain point of view.
== Bug characteristics ==
We find that MITRE’s Common Weakness Enumeration (CWE), Software Fault Patterns, Orthogonal Defect Classification (ODC), and other efforts are good starting points for categories of coding mistakes.
MITRE’s Common Vulnerability Enumeration (CVE) is an effort related to what you suggest: decide whether different failure reports correspond to the same bug. They make that decision all the time, so they may have insight.
-paul-
Paul, thanks for these comments and pointers — I will check them out!
Interesting post!
If we do focus on “code fragments” as bugs, then I think the identification of a bug has to be done relative to the corrected version of the code. There is often more than one way to fix buggy code. As an example, consider the combination of initialization (A), termination codition (B), and the step (C) for an iterator (loop). They have to match properly for the iterator to be correct. If it is buggy (i.e. there is a mismatch), then one may fix it by changing 1-2 of the 3 components, for them to match. Which of the 3 components would we call buggy? And, they don’t seem to fit into your notion of interaction between bugs. If I call A a bug, and B a bug, then C may disappear as a bug, and so on. At least, they don’t seem to interact in the clean way demonstrared in the Venn diagrams.
A corrected version of the code would narrow the choice of which among A,B, and C is a bug. Whether, then, I want to call A and B jointly a bug, or two separate bugs can be treated as a separate problem.
But, exactly for the above reason, I do not like to identify a bug with a code fragment (that needs to be altered/added/removed).
I don’t follow your argument here. In your example, there must be something wrong with fragments A, B, and or C, in order to induce the incorrect execution. Buggy behavior can only arise from a problem in the code. The question I am asking about is: What code is problematic, and do the problematic fragments consist of one bug or many? I think you can have one bug owing to many lines of code — “fragment” is defined loosely. As such, for your example, it seems as if we might have one bug due to code involving combinations of A, B, and C, because we do not have a good reason to argue that elements of the bug are separable.
Say, I want to print natural numbers from 1 to 10. I write the C code:
int a;
for( a = 0; a < 10; a = a + 1 )
{
printf("%d\n", a);
}
which is "buggy". I can fix it the following way:
int a;
for( a = 0; a < 10; a = a + 1 )
{
printf("%d\n", a+1);
}
or, I can fix it the following way:
int a;
for( a = 1; a < 11; a = a + 1 )
{
printf("%d\n", a);
}
or, I can be even more creative (entirely the wrong use of the word!) and fix it the following way:
int a;
for( a = 1; a < 10; a = a + 1 )
{
printf("%d\n", a);
}
printf("%d\n",a);
In each instance, I have changed a different part of the code (or even added new code). What is exactly the bug in the original program?
Very nice example! My definition says that a bug must arise due to the execution of code that’s present, or the non-execution of code that should have been there. You raise a good point that this definition assumes a sort of platonic implementation against which I am mentally diffing the current implementation, to identify which lines created the problem (or failed to not create it). As such, depending on which of your fixes represents the “right” implementation, the location of the bug in the original could change. I don’t think this is a problem, for the purposes of an abstract definition, but obviously it would create a problem for automation, since your choice of platonic implementation would affect the outcome.
It is not a problem, per se. But, even in the abstract case, any bug is uniquely identified by two programs: the buggy one and the correct one.
I think this is important, even without the automation being a factor. Once you make the “platonic” program explicit, your definition of a bug is exactly that diff. My question is then: why try so hard to break up the diff into “atoms” that we can call individual bugs? What is wrong with calling the diff, in its entirety, “a” bug?
Your definition of “bug” refers only to discovered bugs, defective code that does not cause a test case failure is not covered by the definition (why begin by quoting Wikipedia?). For example code that contains an off by one error that does not trigger a test case failure is not yet buggy by this definition, but the defect may be discovered by code review. Is there an implicit attempt here to define bugs as defects in some operational sense, in which case that defect is not really a bug? Programs have both synchronic and diachronic characteristics, with defects emerging over time in response to inputs and in response to the evolution of the code. That means that bugs are partly process and partly static things. You also seem to be assuming that specifications are arbitrarily complex and can pragmatically cover all program behaviour (in the worst case the specification will approach or exceed the size of the program, making it implausibly difficult to construct). For example, bugs in error handling in complex environments are very difficult to specify reasonable test cases for. On occasion, things that are clearly defective behaviour cannot be reproduced with a test case at all and are dealt with by rewriting horrible software components to make them impossible (in which case, localisation to some specific code fragment may not be possible).
Your points show I could have been more clear! I am using the notion of “failure” in an abstract sense. A program, semantically, can be viewed as the set of all the input/output pairs it induces. This set could be infinite. Some of these pairs will be wrong, according to the program’s specification — these are the failures. Some of these failures can be grouped together as owing to the same bug.
I also intended to use the word “specification” in an abstract sense. That is, it could be written down rigorously, or not — but there is some platonic ideal of what the program should be doing, and its bugs might be judged with respect to that ideal. We might not think hard about the shape of the spec until we see the problem behavior, and then in so doing decide whether that behavior is due to one bug or many.
But these definitions are not very operational, which is perhaps a point of your comment. That is, I cannot directly use them to develop the automation I mention at the end, because I don’t have in my hands all possible failures or a full, formal specification of the intended behavior. But thinking through possible definitions was useful at the least to justify an approximation of such automation.
What about the process or evolutionary dimension? Your definition remains an empirical or operational one, it doesn’t stretch to latent defects, but your discussion implicitly includes a time dimension when you want to look at change histories. The act of creating the fixes that you want to review will make those defects visible, which may not have caused any specification-visible errors in the earlier state of the code. Some will more or less fail to fix their intended defect and some will add newly broken behaviour. Are the latent defects not bugs before they are triggered or surfaced by the code change?
Regarding localisation of bug fixes: we know that defects and their associated code changes tend to cluster in specific areas of code, that is just the nature of developed code – there are always defect-prone modules, and changing the code in those high complexity/high latent defect rate components will both add new defects and and make visible new defects, what you need to add to the mix is the idea that this defect nature is also hierarchical, ranging over: “the entire program is wrong, the client wanted a compiler and the team delivered a game”, through: “the wrong version of a report specification was used” to “there is a spelling error”. The relative frequency of these defect levels (and the corresponding degree of localisation in code) is a side-effect of the quality management process applied to the program or system. The more effective the defect removal process, the more localisation there is, but thats not a result of the intrinsic nature of bugs.
Rather than figure out the answer to “what is a bug?” directly, you could also structure the point awards such that the contest participants themselves are incentivized to answer the question for you on a case-by-case basis.
Here’s a simple example from the perspective of the ‘break-it’ team:
* X points for the first issue demonstration.
* No additional points for subsequent issue demonstrations.
* Y additional points if, during the ‘fix-it’ phase, not all of the issues you’ve demonstrated have been fixed.
* NEGATIVE Z points for each demonstration you’ve provided that ends up getting fixed.
There are still some perverse incentives with this particular arrangement (regarding whether/how-much to gamble for the Y additional points), but it might be a nice starting point for better ideas.
Very interesting idea — thanks!
I would like to submit a different perspective on bugs. As I am not a native english speaker, some concepts might get lost in translation. Please keep that in mind while reading the following.
Programs operate as written unless there is some hardware malfunction or a compiler error. As such the bugs are not in the program but somewhere along the path of the understanding of the problem, the development of the solution and in the actual writing of the solution in a computer language.
The program does what was written, not what you think or want it to do. I guess if a system fails to live up to the expectations one has of it you could call that a bug, but in my view it is the builder of the system that has a problem not the system itself.
Lets take the example of a house that is built with a beam that is too weak and it eventually collapses. We can say that the house is defective or that it failed. But the error lies with the builder who tried to save costs by using a smaller/cheaper beam, or maybe it lies with the architect or engineer that made a faulty calculation and designed the house with the weak beam.
The point I am trying to make is that programs may exhibit defects but the errors or bugs lie with the humans that build and design them.
Hello Michael, your co-author (in ICST 2016) has directed me to this site. I am not sure you are still interested in this question, so I will be brief for a first attempt at answering your question.
so here goes: any definition of a fault must be based on some level of granularity in the source code, which is as fine as you want the localisation of the fault to be precise. I call feature any piece of source code at the selected level of granularity.
with this definition of a feature, a fault in program P with respect to specification R is any feature f that admits a substitute that would make the program more-correct.
if this looks interesting, I can discuss with you what it means for a program P’ to be more-correct than a program P with respect to a specification R.
Pingback: What is soundness (in static analysis)? - The PL Enthusiast
Pingback: Evaluating Empirical Evaluations (for Fuzz Testing) - The PL Enthusiast