
[This guest post is by David Walker, a professor at Princeton, and recent winner of the SIGPLAN Robin Milner Young Researcher Award. –Mike]
Every once in a while it is useful to take a step back and consider where fruitful new research directions come from. One such place is from the confluence of two independent streams of thought. This is an idea that I picked up from George Varghese, who gave a wonderful talk on the topic at ACM SIGCOMM 2014 and summarized the ideas in a short paper for CCR.[ref]George Varghese. Life in the Fast Lane: Viewed from the Confluence Lens. ACM SIGCOMM Computer Communication Review 45 (1), pp 19-25, January 2015. (link)[/ref] This blog post considers confluences in the context of programming languages research, reflects upon the role such confluences have played in my own research, and suggests some things we might learn from the process. My keynote talk from POPL 2016[ref]David Walker. Confluences in Programming Languages Research (Keynote). ACM SIGPLAN Symposium on Principles of Programming Languages. pp. 4-4, January 2016. (abstract, video, slides)[/ref] touches on many of these same themes.
Confluences in Research
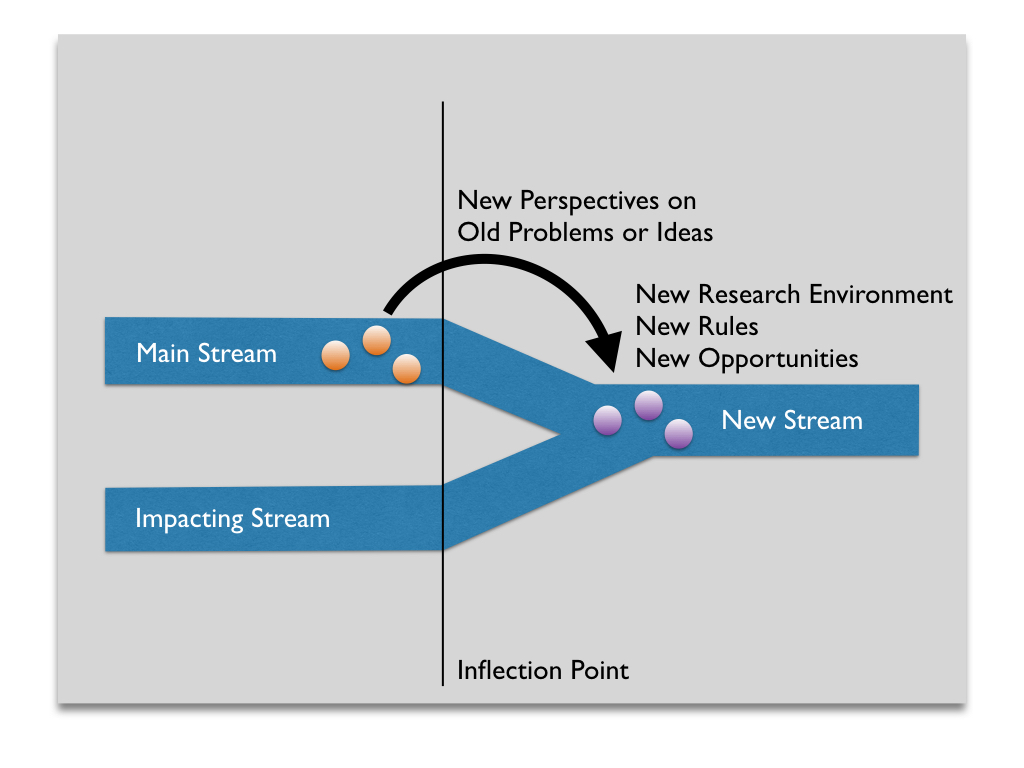
According to George’s definition, a confluence has several features:
- Researchers engage with two different streams of thought independently at first. Often one stream may be thought of as the “main stream” that holds the central ideas and the other stream may be thought of the “impacting stream,” which will eventually influence those ideas.
- At a certain point, an event in the “real world” causes a change in one or both of the streams, allowing them to come together. We call this event the inflection point.
- The combination of the two streams produces a fundamentally different environment for research.
The image below visualizes a generic confluence.
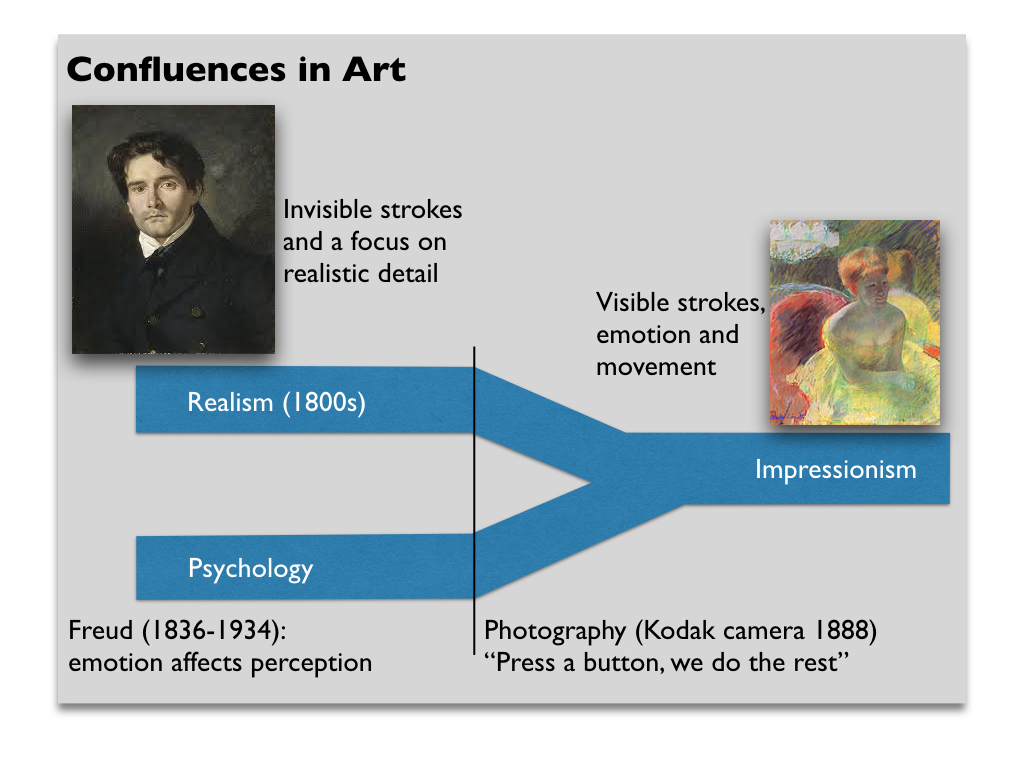
A beautiful example of a confluence, due to Varghese, comes from the art world. Beginning in late 1840s, realism became one of the dominant art forms in the Western world. Realism was characterized by attention to detail and an attempt to represent reality on canvas as accurately as possible. However, later in the 1800s, photography was developed. In 1888, Kodak introduced their first camera to the world with the tagline “press a button and we do the rest.” Now, realist painters were not the only ones who could faithfully recreate everyday life on canvas — anyone could do it. Hence the invention and widespread adoption of the camera became a key inflection point for the art world.
At the same time as the art world was being shaken by photography, the discipline of psychology was being developed. One of the key figures in this secondary stream of thought was Freud and one of Freud’s central hypotheses was that emotion influences perception. The impressionists and post-impressionists, whether they had read Freud or not, adopted these principles and began to interpret the world more subjectively, seeing it through the lens of their own emotions and mental state. For instance, in one letter to his brother, Van Gogh writes the following about The night café [ref]Liz Hager. The color of genius: Van Gogh’s Night Café. December, 2008. (link)[/ref]:
In my picture of the “Night Café” I have tried to express the terrible passions of humanity by means of red and green. . . the café is a place where one can ruin oneself, go mad or commit a crime.”
The night café is not an objective rendering of a bar; it is the world transformed by Van Gogh’s distress.

In summary, realism was disrupted by an inflection point, the invention of the camera, and then influenced by a secondary stream of thought, psychology, and this confluence of events gave rise to impressionism, post-impressionism and other modern movements.
Confluences in PL Research
When it comes to programming languages research, we see many confluences. One of my favorites involves the confluence of operating system reliability and model checking. In the early 1980s, Ed Clarke and Allen Emerson developed model checking, [ref]E. M. Clarke and E. A. Emerson, The Design and Synthesis of Synchronization Skeletons Using Temporal Logic, Proceedings of the Workshop on Logics of Programs, IBM Watson Research Center, Yorktown Heights, New York, Springer-Verlag Lecture Notes in Computer Science, #131, pp. 52–71, May 1981. (link)[/ref] the process of exhaustively checking whether a state machine satisfies a given logical specification. More formally, according to Clarke:[ref]E. M. Clarke. The Birth of Model Checking. In “25 Years of Model Checking.” Ed Orna Grumfield and Helmut Veith, pp 1-26, 2008. (link)[/ref] if M is a Kripke structure (i.e., the state machine) and F is a formula in temporal logic, then model checking involves finding all states s of M such that (M, s) satisfies the formula F.
Initially, model checking was a fairly preposterous idea — on computers at the time, the initial algorithms could only hope to check models on the order of 1000 states. However, any useful program or piece of hardware was bound to have many, many orders of magnitude more states than that – millions or billions or more states. In addition, software components can have infinitely many states. Would model checking ever be of any use?
Fast forward a couple of decades, and the combination of new, better algorithms, improved data structures (such as BDDs), vastly improved hardware, and new techniques for program abstraction, meant that suddenly model checking was not so implausible as it was before. By the early 1990s, it was possible to check some models with upwards of 10^20 states and since then, we have been able to check some models with up to 10^120 states![ref]E. M. Clarke. The Birth of Model Checking. In “25 Years of Model Checking.” Ed Orna Grumfield and Helmut Veith, pp 1-26, 2008. (link)[/ref]
The inflection point here is a bit blurrier than in the invention of the camera, but there is an inflection point (or perhaps many inflection points) nonetheless. An inflection point occurred when model checking algorithms suddenly enabled verification or synthesis in some important new domain. Interestingly, and somewhat contrary to Varghese’s idea that an inflection point arises due to an event in the “real world,” in this case the inflection point occurred due to developments in basic research. In programming languages, perhaps moreso than networking, it is not uncommon for breakthroughs in basic research to give rise to new, qualitatively different opportunities.
 At the same time as model checking was being developed through the 80s and 90s, a rather large company was struggling with the reliability of its operating system. Too often, its customers complained of the infamous blue screen of death. However, these blue screens of death often weren’t directly or exclusively the fault of said operating system vendor. They arose due to the interactions between the OS and 3rd party device drivers. More specifically, the Windows Driver Model (WDM) is an interface of roughly 800 function calls (circa 2004) that are used by drivers writers to interact with the kernel.[ref]Thomas Ball, Byron Cook, Vladimir Levin and Sriram K. Rajamani. SLAM and Static Driver Verifier: Technology Transfer of Formal Methods inside Microsoft. Microsoft Corporation. 2004. (link)[/ref] There are a host of rules that go along with the use of such functions and deviations from these usage rules can cause the entire system to crash. Though individual drivers may be relatively small, the complexity of the interactions with the kernel and lack of protections in kernel mode make these drivers the source of disproportionately many critical bugs.
At the same time as model checking was being developed through the 80s and 90s, a rather large company was struggling with the reliability of its operating system. Too often, its customers complained of the infamous blue screen of death. However, these blue screens of death often weren’t directly or exclusively the fault of said operating system vendor. They arose due to the interactions between the OS and 3rd party device drivers. More specifically, the Windows Driver Model (WDM) is an interface of roughly 800 function calls (circa 2004) that are used by drivers writers to interact with the kernel.[ref]Thomas Ball, Byron Cook, Vladimir Levin and Sriram K. Rajamani. SLAM and Static Driver Verifier: Technology Transfer of Formal Methods inside Microsoft. Microsoft Corporation. 2004. (link)[/ref] There are a host of rules that go along with the use of such functions and deviations from these usage rules can cause the entire system to crash. Though individual drivers may be relatively small, the complexity of the interactions with the kernel and lack of protections in kernel mode make these drivers the source of disproportionately many critical bugs.
The confluence occurred when Tom Ball and Sriram Rajamani recognized that research in model checking technology had matured to the point where it could be applied to the domain of device driver verification. These drivers were a particularly good target because the need for improvement (and the financial reward for doing so) was high, and yet the domain was tractable: Though drivers have complex control-flow and interactions with the kernel, they often use relatively few heap-allocated data structures. Consequently, the state space that a model checker must explore is more limited than it would be for a general-purpose program. In short, the structure of the application domain made it a perfect fit for an area of basic programming languages research that was nearing maturity.
Other Confluences in Programming Languages Research
The confluence of model checking and operating system reliability led to many exciting research opportunities, but this is just one of many confluences that involves programming research. To mention just a few others:
- Network configuration and structured programming: Software-defined networking is a new architecture for controlling the configuration of modern data center and wide-area networks. This inflection point disrupted the networking industry and created an opportunity for programming languages researchers to define new, principled, high-level abstractions for controlling networks. In the Frenetic project, my colleagues and I have been using what we know about structured programming and compositional reasoning to provide better interfaces for network programmers and operators. More on this confluence in my POPL 2016 keynote.
- Motorized vehicles and formal methods: For 100 or so years, the primary threat model when driving a car was running into something: a horse, another car, a bus or the ditch. However, within the last decade, cars have been connected to the internet. Consequently, cars and other vehicles are now vulnerable to a whole new array of threats. For instance, security researchers recently showed they could remotely hack into a jeep driving down the highway. DARPA’s HACMS project, conceived by Kathleen Fisher, seeks to use formal methods to help defend against these new threats.
- Machine learning and programming language design: In order to make development of a programming language worthwhile, one must have a sufficient number of users. Over the last few years, the success of deep learning (and other kinds of machine learning) has created an inflection point that has driven up the demand for new programming languages or frameworks that make it easier to use such technologies, even if the user is not a machine learning expert. Google’s TensorFlow is one high-profile example of research at the intersection of programming languages and machine learning, but there are many other exciting developments in this space as well.[ref]Mike: Probabilistic programming is another, as detailed in a prior PL Enthusiast post.[/ref]
- Untyped and typed programming: Untyped languages are enticing little devils. They often make it easy for programmers to get started on a project by writing little scripts. Time and again though, it has been shown that once the software base reaches a certain size, one needs a type system to help document and control module interactions. However, if you started with an untyped language, you are often stuck at a certain point with too much untyped code to throw away, but not enough linguistic support to make efficient forward progress. Many researchers had been studying the combination of static and dynamic type systems for a while, but when a massive company like Facebook fell into the trap of untyped languages (in the form of PHP), these ideas gained a whole lot more mainstream exposure. Facebook invented Hack, a language with a gradual type system, which layers statically types over a dynamic language. Microsoft’s Typescript is another example of the kind of system that can emerge from the confluence of typed and untyped languages.
Forseeing Inflection Points
More broadly, it is useful to think about how confluences arise so we can keep our eyes out for the next one and take advantage. In particular, I think it is important to try to identify key inflection points. These inflection points can arise for any number of reasons: a change in basic computational hardware, sensors, devices or other technology, a change in the scale of some problem, or its complexity, a change in the economy or our society, or a breakthrough in basic research. Identifying true inflection points — those that will not soon be reversed — can help us separate mere fads from meaningful changes in our computing environment and hence point us to research problems whose solutions may have long-lasting impact. Moreover, by identifying inflection points early, we can start work on providing solutions in an application domain before inferior alternative methods become entrenched. Early in the process, thought leaders in the application area may be more open-minded to the unusual, but effective kinds of solutions we may bring to the table as they have fewer existing alternatives and their opinions on the matter may not yet have hardened.
Of course, identifying inflection points early is no easy task. The expertise of most programming language researchers lies in, well, programming languages. It is tough to be an expert in programming language semantics or algorithms and also an expert in machine learning or biology or distributed systems or databases. There is a lot to know about PL and an equally large amount to know about each one of those other fields.
The solution, in my opinion, is not to try to know it all, but instead to build relationships with people in other fields. In other words, “make friends” — find the person inside your computer science department, or outside your department, doing the most interesting thing other than programming languages research. Be sure it is someone open-minded who you can communicate with. Then hang out with that person for a while to find out something about what they do. There are a bunch of great ways to “hang out” with fellow researchers: have lunch or coffee with them on a regular basis, asking one simple question each time; go to all of their PhD student talks; take a class from them and do the homework; write a grant proposal with them; share a PhD student or post doc.
What else can we do to take advantage of, or perhaps to generate, confluences in programming languages research?
Deep Education in PL
One key is clearly to give our graduate students the right education. In my opinion, such an education first involves training in deep, highly-reusable programming languages skills.[ref]Mike: This is also a point that Peter O’Hearn made in his interview.[/ref] We want the skills we teach to be deep because it is easy to pick up the shallow ones later on and on demand — the deep ones often take the kind of time that one can only find as a grad student. And of course we want the skills to be highly reusable, so students can deploy them in a wide variety of scenarios after they graduate.
In my case, as a PhD student, I studied the design and meta-theory of type systems as well as the design of “little languages” that extract the essence of, and model, computationally interesting phenomena. Both of these generic skills take significant time to learn and much practice to perfect, but the long-term investment has served me very well throughout my career. Because they are so generic, and powerful, I have been able to apply them to a wide range of problems from data processing to network configuration to protection against memory faults. In most cases, I could not possibly have imagined studying these topics when I was in grad school, but great preparation, and acquisition of general-purpose skills, allowed me to make an impact anyway.
Of course, there are many other basic PL skills of this nature that I do not know, but can and do serve others equally well for similar reasons: skills in the construction and use of logical frameworks, interactive theorem provers, SMT solvers, various proof techniques for program and programming language properties, static and dynamic program analysis, type inference, testing techniques, and library design to name just a few. Now, while teaching our students core skills it is nice to expose them to research outside their narrow area, and to encourage curiosity; but the core skills are the truly indispensable part.
Pitfalls
I would be remiss if I did not mention some of the difficulties in identifying inflection points and in exploiting the benefits of potential confluences.
In particular, breaking into new fields will take time, even with the best collaborators. Personally, I have found it takes at least a year or two of immersing oneself in a new area before things get going, if they ever do. For instance, in my work on the Frenetic Project, we started work in the fall of 2009, but we did not see the first paper published until the fall of 2011,[ref]Nate Foster, Rob Harrison, Michael J. Freedman, Christopher Monsanto, Jennifer Rexford, Alec Story, and David Walker. Frenetic: A Network Programming Language. In ACM SIGPLAN International Conference on Functional Programming (ICFP), Tokyo, Japan, September 2011. (link)[/ref] and that project has gone as well as we could possibly hope. One or two years may be a highly optimistic timeline for many endeavors. The deeper, and more technically challenging the new field, the greater the investment one will have to make, though the reward may also be greater in the end.
Moreover, interdisciplinary efforts fail all the time, or at least are less than completely successful. A failure often happens when one simply cannot identify much useful, uniform, exploitable structure in the domain. It would be nice if we could identify the structure first and then dig in to the topic later when we had a guarantee there was something exciting there. Unfortunately, one cannot always expect to see such structure just by glancing at superficial elements of the problem domain. Indeed, the more significant contributions may come when the structure is less obvious at first. Consequently, digging into these new topics involves some risk, like much other research. In order to mitigate the risk of failure, I often try to have one hand in a new area I am learning, and may not pan out, and another hand in some older area where I am more confident. Finding a great collaborator also mitigates the risk somewhat.
Summary
Confluences in programming languages research are worth finding because they can open up exciting new ideas for exploration. This is especially true of confluences between basic research and applications. The road to getting there may not be easy, but the payoff is significant. Such confluences also point to the importance of basic research in PL — it is the long term research on general-purpose foundations of programming languages that eventually make them helpful in solving such a wide range of domain-specific problems. Hence, if we want to continue to increase the impact of PL on the world, what we need most is diversity: We need some to forge ahead with basic research while others work on short-term, industry-driven needs, and still others speculate about the future and our programming requirements 20, 30 or 50 years down the line. Such diversity of thought and enterprise will lead us through a golden age of programming languages research.