
A few weeks ago, I posted about an analysis of collaboration in the POPL community. In that post, I promised similar analyses for a few other conference-defined communities as well. Well, here they are. In this post, I will report on an analysis of community structure in two other premier SIGPLAN conferences: PLDI and OOPSLA.
Methodology
The methodology for the analysis was similar to that in my earlier post on POPL. The questions I asked were:
- Who works with whom in the community defined by a conference X?
- Are there prominent clusters of researchers who frequently publish papers with each other?
- Which papers/researchers are at the center of the community (that is, who are the Kevin Bacons of community X)?
To answer these questions, I used data from the DBLP database to construct, for each conference, an overlap graph: a graph where nodes represent papers with more than 1 author published in the period 2005-2014, and edges connect pairs of papers that have at least one author in common. For each graph, I generated the set of connected components (which correspond to disjoint subcommunities) and ran some further analyses on the largest component.
PLDI
Here are the results I got for PLDI.
Like POPL, PLDI had a large connected component in its overlap graph. The conference published 381 papers with more than 1 author in the period 2005-2014, and the largest component contained 229 of these papers. In contrast, the second largest component had just 7 papers. Here is a visualization of the largest component (click the image for a larger version).
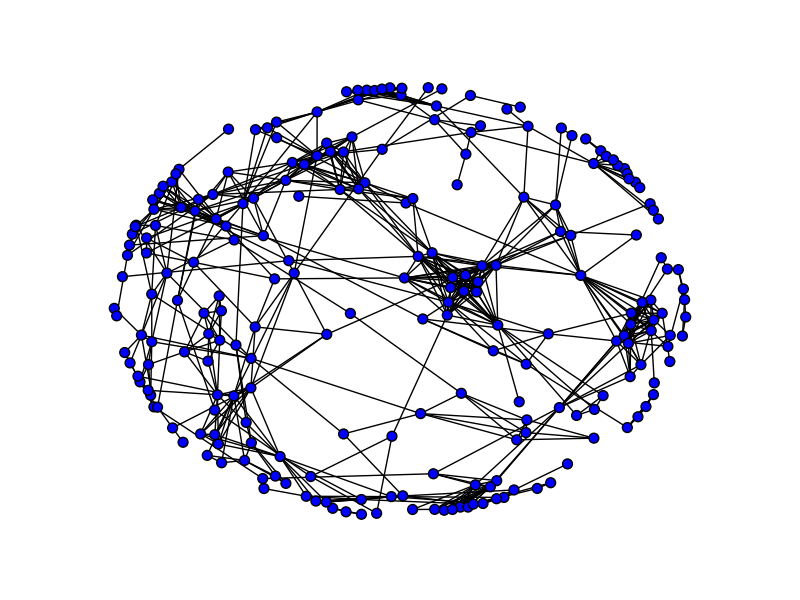
The largest component has a diameter of 13, which is smaller than POPL’s 18. However, the average length of the shortest path between two nodes in this graph is 5.64, which is similar to POPL’s. Given that the average distance between two users in the Facebook friendship graph is 4.74, this suggests that PLDI isn’t quite a tightly connected community.
Next I did a community analysis on this component graph. Technically, my analysis computed a k-clique community: the union of all cliques of size k that can be reached through “adjacent” k-cliques, where two k-cliques are adjacent if they share (k – 1) nodes. Here, k is a parameter, and you can discover interesting collaboration patterns by varying its value. The largest community for any value of k contained the following authors:
Sumit Gulwani; Saurabh Srivastava; Ramarathnam Venkatesan; Susmit Jha; Ashish Tiwari; Thomas Ball; Daniel Perelman; Dan Grossman; Peter Provost; Sagar Jain; Eric Koskinen; Vijay Anand Korthikanti; Florian Zuleger; Sigmund Cherem; Trishul M. Chilimbi; Armando Solar-Lezama; Rishabh Singh; William R. Harris; Vu Le; Jeffrey S. Foster; Swarat Chaudhuri; Aleksandar Chakarov; Sriram Sankaranarayanan
The community was pretty clearly centered around Sumit Gulwani, as he was an author in all but one paper in it.
To find the researchers at the center of the (entire) community, I computed the center of the community graph: the set of nodes that whose maximal distance to other nodes in the graph is minimal. While the center of POPL had just 2 papers, PLDI’s center had 7. Each paper in the center was at most 8 edges away from other papers. Here are the 7 papers:
- “Thread-modular shape analysis.”Alexey Gotsman, Josh Berdine, Byron Cook, Mooly Sagiv
- “Precise and compact modular procedure summaries for heap manipulating programs.” Isil Dillig, Thomas Dillig, Alex Aiken, Mooly Sagiv
- “JANUS: exploiting parallelism via hindsight.” Omer Tripp, Roman Manevich, John Field, Mooly Sagiv
- “VeriCon: towards verifying controller programs in software-defined networks.” Thomas Ball, Nikolaj Bjorner, Aaron Gember, Shachar Itzhaky, Aleksandr Karbyshev, Mooly Sagiv, Michael Schapira, Asaf Valadarsky
- “Mixing type checking and symbolic execution.” Yit Phang Khoo, Bor-Yuh Evan Chang, Jeffrey S. Foster
- “Thresher: precise refutations for heap reachability.” Sam Blackshear, Bor-Yuh Evan Chang, Manu Sridharan
- “Concurrent data representation synthesis.” Peter Hawkins, Alex Aiken, Kathleen Fisher, Martin C. Rinard, Mooly Sagiv
It seems from this that Mooly Sagiv is the Kevin Bacon of the PLDI community. (And Sumit, perhaps is the Paul Erdos.)
OOPSLA
I ran a similar analysis on data about OOPSLA. Interestingly, the largest component in OOPSLA’s overlap graph was smaller than POPL’s and PLDI’s. Specifically, OOPSLA published 325 multiple-author papers in the period 2005-2014, and of these, 145 were in the largest component. This doesn’t mean that the other components were large, however — the second-largest component had only 17 papers.
Here is the largest component in the OOPSLA overlap graph.
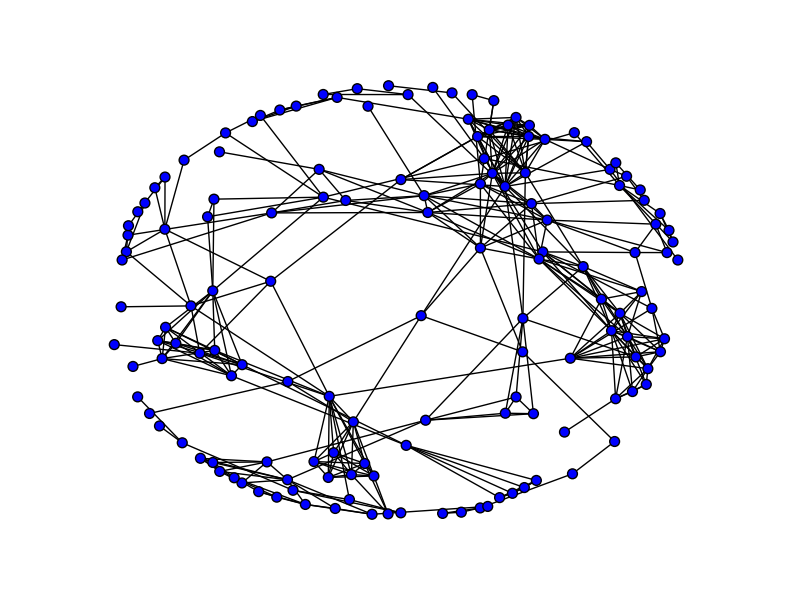 The diameter of the component is 11. The average length of the shortest path between two nodes in the graph is 4.96. The largest k-clique community has the following authors:
The diameter of the component is 11. The average length of the shortest path between two nodes in the graph is 4.96. The largest k-clique community has the following authors:
T. Scott Saponas; Ryder Ziola; Todd Mytkowicz; Kathryn S. McKinley; Aman Kansal; A. J. Bernheim Brush; Michael Hicks; Suriya Subramanian; Stephen Magill; Sooel Son; Vitaly Shmatikov; Stephen W. Kent; Samuel Z. Guyer; Michael D. Bond; Nicholas Nethercote; Amer Diwan; Byeongcheol Lee; Martin Hirzel; Robert Grimm; Katherine E. Coons; Madan Musuvathi; Matthew Arnold; Stephen M. Blackburn; Jungwoo Ha; Rifat Shahriyar; Xi Yang; Daniel von Dincklage; Asjad M. Khan; Han Bok Lee; Rotem Bentzur; Thomas VanDrunen; Antony L. Hosking; Maria Jump; Daniel Frampton; J. Eliot B. Moss; Robin Garner; Chris Hoffmann; Aashish Phansalkar; Daniel Feinberg; Ben Wiedermann; Darko Stefanovic; Jennifer B. Sartor; Xi Yang
This community was clearly centered around Kathryn McKinley, who co-authored every paper in it.
The center of OOPSLA had just one paper:
- “Safe futures for Java.” Adam Welc, Antony L. Hosking, Suresh Jagannathan.
The maximal distance between this paper and any other OOPSLA paper was 6.
Changes over time
An intriguing question is whether collaboration patterns in the conferences that I studied have changed over time. All these conferences have changed in character in recent times. OOPSLA started out as a conference on object-oriented programming; however, in recent times, it has broadened into a venue for papers on “all aspects of programming languages and software engineering, broadly construed” (to quote the website). POPL was heavily focused on types and semantics in the 1990s; now it also publishes many papers that would traditionally fit CAV and PLDI. Also, the research world at large has changed. Because of the internet, long-distance collaborations among researchers are now easier than they used to be. Also, due to a variety of reasons, researchers today tend to write more papers than researchers from 15-20 years ago. It’s possible that these changes would change the shape of the collaboration graphs.
To investigate this, I ran my analysis on papers published in POPL, PLDI, and OOPSLA in the period 1995-2004. The results are remarkable. It turns out that the graphs generated from this period do not have large connected components. Specifically, POPL, PLDI, and OOPSLA published 196, 230, and 235 multi-author papers during this time, respectively. However, the largest and second largest components in POPL’s overlap graph from this period only contain 25 and 23 papers, respectively. The corresponding numbers for PLDI are 22 and 19, and those for OOPSLA are 48 and 29. So, the phenomenon of a largely connected community is a more recent one.
The takeaway
What does this analysis tell us, in the end? For one, it unveils some similarities amongst collaboration patterns in the POPL, PLDI, and OOPSLA communities. In each of these communities, we have a large cluster of connected papers written by certain long-standing members. Papers not linked to this cluster do get written, but they tend to be one-off efforts. At the same time, in all these conferences, papers in the giant connected component aren’t connected all that tightly. The average distance between two papers in these components is greater than the average distance between two users in the Facebook friendship graph.
The analysis also identifies certain research leaders who contribute prolifically to a conference over a period of time, and bring together disparate groups of researchers through collaboration. Specifically, it selects Peter O’Hearn as the hub of the largest such sub-community within the POPL community. As we see above, Sumit Gulwani and Kathryn McKinley take on these roles in PLDI and OOPSLA. Also, the analysis points out some “central” papers in each conference community. These papers, within the closest possible proximity to other papers in the conference, can perhaps be taken to be representative of what the conference tends to publish.
Finally, comparison with collaboration data from an earlier period suggests that PL as a discipline is not in any danger of fragmentation. In fact, we are closer to each other than we were back in the day.
Hi. I really enjoyed these series of posts analysing collaboration of major PL conferences, fantastic work! 🙂
Would you be willing to perform the same kind of analysis of major systems conferences, such as OSDI/SOSP? If not, could you share your code?
Again, really interesting read. Thanks!
Yes, I plan to put the code on Github. I have to clean it up a bit, but I’ll do that as soon as the semester is over (in a few weeks).