
The PLUM reading group recently discussed the paper, DR CHECKER: A Soundy Analysis for Linux Kernel Drivers, which appeared at USENIX Securty’17. This paper presents an automatic program analysis (a static analysis) for Linux device drivers that aims to discover instances of a class of security-relevant bugs. The paper is insistent that a big reason for DR CHECKER’s success (it finds a number of new bugs, several which have been acknowledged to be true vulnerabilities) is that the analysis is soundy, as opposed to sound. Many of the reading group students wondered: What do these terms mean, and why might soundiness be better than soundness?
To answer this question, we need to step back and talk about various other terms also used to describe a static analysis, such as completeness, precision, recall, and more. These terms are not always used in a consistent way, and they can be confusing. The value of an analysis being sound, or complete, or soundy, is also debatable. This post presents my understanding of the definitions of these terms, and considers how they may (or may not) be useful for characterizing a static analysis. One interesting conclusion to draw from understanding the terms is that we need good benchmark suites for evaluating static analysis; my impression is that, as of now, there are few good options.
Soundness in Static Analysis
The term “soundness” comes from formal, mathematical logic. In that setting, there is a proof system and a model. The proof system is a set of rules with which one can prove properties (aka statements) about the model, which is some kind of mathematical structure, such as sets over some domain. A proof system L is sound if statements it can prove are indeed true in the model. L is complete if it can prove any true statement about the model. Most interesting proof systems cannot be both sound and complete: Either there will be some true statements that L cannot prove, or else L may “prove” some false statements along with all the true ones.
We can view a static analysis as a proof system for establishing certain properties hold for all of a program’s executions; the program (i.e., its possible executions) plays the role of the model. For example, the static analyzer Astrée aims to prove the property R, that no program execution will exhibit run-time errors due to division by zero, out-of-bounds array index, or null-pointer dereference (among others). Astrée should be considered sound (for R) if, when it says the property R holds for some program, then indeed no execution of the program exhibits a run-time error. It would be unsound if the tool can claim the property holds when it doesn’t; i.e., when at least one execution is erroneous. My understanding is that Astrée is not sound unless programs adhere to certain assumptions; more on this below.
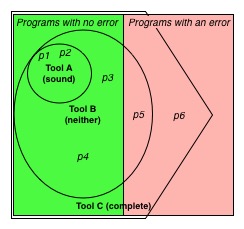
Soundness and completeness, visualized
The figure to the right shows the situation visually. The left half of the square represents all programs for which property R holds, i.e., they never exhibit a run-time error. The right half represents programs for which R does not hold, i.e., some executions of those programs exhibit an error. The upper left circle represents the programs that an analyzer (tool) A says satisfy R (which include programs p1 and p2); all programs not in the circle (including p3-p6) are not proven by A. Since the circle resides entirely in the left half of the square, A is sound: it never says a program with an error doesn’t have one.
False Alarms and Completeness
A static analysis generally says a program P enjoys a property like R by emitting no alarms when analyzing P. For our example, tool A therefore emits no alarm for those programs (like p1 and p2) in its circle, and emits some alarm for all programs outside its circle. For the programs in the left half of the figure that are not in A‘s circle (including p3 and p4) these are false alarms since they exhibit no run-time error but A says they do.
False alarms are a practical reality, and a source of frustration for tool users. Most tool designers attempt to reduce false alarms by making their tools (somewhat) unsound. In our visualization, tool B is unsound: part of its circle includes programs (like p5) that are in the right half of the square.
At the extreme, a tool could issue an alarm only if it is entirely sure the alarm is true. One example of such a tool is a symbolic executor like KLEE: Each error it finds comes with an input that demonstrates a violation of the desired property. In the literature, such tools—whose alarms are never false—are sometimes called complete. Relating back to proof theory, a tool that emits no alarms is claiming that the desired property holds of the target program. As such, a complete tool must not issue an alarm for any valid program, i.e., it must have no false alarms.
Returning to our visualization, we can see that tool C is complete: Its pentagon shape completely contains the left half of the square, but some of the right half as well. This means it will prove property R for all correct programs but will also “prove” it (by emitting no alarm) for some programs that will exhibit a run-time error.
Soundiness
A problem with the terms sound and complete is that they do not mean much on their own. A tool that raises the alarm for every program is trivially sound. A tool that accepts every program (by emitting no alarms) is trivially complete. Ideally, a tool should strive to achieve both soundness and completeness, even though doing so perfectly is generally impossible. How close does a tool get? The binary soundness/completeness properties don’t tell us.
One approach to this problem is embodied in a proposal for an alternative property called soundiness. A soundy tool is one that does not correctly analyze certain programming patterns or language features, but for programs that do not use these features the tools’ pronouncements are sound (and exhibit few false alarms). As an example, many Java analysis tools are soundy by choosing to ignore uses of reflection, whose correct handling could result in many false alarms or performance problems.
This idea of soundiness is appealing because it identifies tools that aim to be sound, rather than branding them as unsound alongside many far less sophisticated tools. But some have criticized the idea of soundiness for the reason that it has no inherent meaning. It basically means “sound up to certain assumptions.” But different tools will make different assumptions. Thus the results of two soundy tools are (likely) incomparable. On the other hand, we can usefully compare the effectiveness of two sound tools.
Rather than (only) declare a tool to be soundy, we should declare it sound up to certain assumptions, and list what those assumptions are. For example, my understanding is that Astrée is sound under various assumptions, e.g., as long as the target program does not use dynamic memory allocation. [Edit: There are other assumptions too, including one involving post-error execution. See Xavier Rival’s comment below.]
Precision and Recall
Proving soundness up to assumptions, rather than soundness in an absolute sense, still does not tell the whole story. We need some way of reasoning about the utility of a tool. It should prove most good programs but few bad ones, and issue only a modicum of false alarms. A quantitative way of reporting a tool’s utility is via precision and recall. The former is a measure that indicates how often that claims made by a tool are correct, while the latter measures what fraction of possibly-correct claims are made.
Here are the terms’ definitions. Suppose we have N programs and a static analysis such that
- X of N programs exhibit a property of interest (e.g., R, no run-time errors)
- N-X of them do not
- T ≤ X of the property-exhibiting programs are proved by the static analysis; i.e., for these programs it correctly emits no alarms
- F ≤ N-X of the property-violating programs are incorrectly proved by the analysis; i.e., for these programs it is incorrectly silent
Then, the static analysis’s precision = T/(T+F) and its recall = T/X.
A sound analysis will have perfect precision (of 1) since for such an analysis we always have F=0. A complete analysis has perfect recall, since T=X. A practical analysis falls somewhere in between; the ideal is to have both precision and recall scores close to 1.
Recall our visualization. We can compute precision and recall for the three tools on programs p1-p6. For these, N=6 and X=4. For tool A, parameter T=2 (i.e., programs p1 and p2) and parameter F=0, yielding precision=1 (i.e., 2/2) and recall=1/2 (i.e., 2/4). For tool B, parameter T=4 (i.e., programs p1-p4) and F=1 (i.e., program p5), so it has precision=4/5 and recall=1. Finally, tool C has parameter T=4 and F=2 (i.e., programs p5 and p6), so it has precision=2/3 and recall=1.
Limitations of Precision and Recall
While precision and recall fill in the practical gap between soundness and completeness, they have their own problems. One problem is that these measures are inherently empirical, not conceptual. At best, we can compute precision and recall for some programs, i.e., those in a benchmark suite (like p1-p6 in our visualization), and hope that these measures generalize to all programs. Another problem is that it may be difficult to know when the considered programs do or do not exhibit a property of interest; i.e., we may lack ground truth.
Another problem is that precision and recall are defined for whole programs. But practical programs are sufficiently large and complicated that even well engineered tools will falsely classify most of them by emitting a few alarms. As such, rather than focus on whole programs, we could attempt to focus on program bugs. For example, for a tool that aims to prove array indexes are in bounds, we can count the number of array index expressions in a program (N), the number of these that are properly in bounds (X), and the number the tool accepts correctly by emitting no alarm (T) and those it accepts incorrectly by failing to emit an alarm (F). By this accounting, Astrée would stack up very well: It emitted only three false alarms in a 125,000 line program (which presumably has many occurrences of array index, pointer dereference, etc.).
This definition still presents the problem that we need to know ground truth (i.e., X) which can be very difficult for certain sorts of bugs (e.g., data races). It may also be difficult to come up with a way of counting potential bugs. For example, for data races, we must consider (all) feasible thread/program point combinations involving a read and a write. The problem of counting bugs raises a philosophical question of what a single bug even is—how do you separate one bug from another? Defining precision/recall for whole programs side-steps the need to count.
Conclusion
Soundness and completeness define the boundaries of a static analysis’s effectiveness. A perfect tool would achieve both. But perfection is generally impossible, and satisfying just soundness or completeness alone says little that is practical. Precision and recall provide a quantitative measure, but these are computed relative to a particular benchmark suite, and only if ground truth is known. In many cases, the generalizability of a benchmark suite is unproven, and ground truth is uncertain.
As such, it seems that perhaps the most useful approach for practical evaluation of static analysis is to make universal statements—such as soundness or completeness (up to assumptions) which apply to all programs—and empirical statements, which apply to some programs, perhaps with uncertainty. Both kinds of statements give evidence of utility and generalizability.
To do this well, we need benchmark suites for which we have independent evidence of generalizability and (at least some degree of) ground truth. My impression is that for static analysis problems there is really no good choice. I would suggest that this is a pressing problem worth further study!
Thanks to Thomas Gilray, David Darais, Niki Vazou, and Jeff Foster for comments on earlier versions of this post.
Dear Mickael,
Nice Article. Thanks. You are right about the need for clear definitions.
I’m not fully convinced by your example about Astrée. A tool like Astrée should not “assume” there is no dynamic allocation because it has the inference power to “check” this hypothesis. If it finds a dynamic allocation (it analyses complete programs), il will return “I don’t know (because your program is too complicated for me)” and stop here. This is sound and its removes this specific hypothesis.
[The main “problem” behind Astrée soundness is that Astrée is so precise that is it very fragile with respect to the C semantics. The less precise is your analysis, the less you care with subtleties of the target programming language semantics.]
A better example for me is the previous tool for static contract checking, developed by Francesco Logozzo and Manuel Fähndrich at Microsoft. It made assumptions about the non-aliasing of method parameters, and I don’t think it could check this assumption on its own.
This is a good point. When reading the paper on soundiness it mentions reflection as being a common feature that Java analyses ignore. But as you say: Why ignore it when you can detect it and complain?
Perhaps the point is that even if the feature is present, ignoring it and reporting results might be more useful than simply failing. The same could be true for Astrée when run on programs with malloc/free. This seems to relate to your point about precise semantics, but I’ll have to think more, to connect the dots.
Nice article, thanks! One point I can’t help but bring up is that I think it’s exceedingly difficult to technically distinguish “sound subject to assumptions” and “sound with respect to a model”, as every model implicitly or explicitly builds in assumptions. It seems to me that much of the discussion across the community has under-emphasized that “sound” is a relation.
This is a great point. The model is not one-size-fits-all; you can have different models that make different assumptions about execution, e.g., what happens if you access a buffer outside its bounds. Peter O’Hearn also pointed this out to me separately, and it makes sense. Thanks!
This is a nice article. Thanks for writing it.
One major reason to be having this discussion on soundness is the politics of using it to accept or reject papers. I think it is imperative to understand that disliking a paper because stated assumptions are perceived as unrealistic is dramatically different than disliking a paper because assumptions are not stated. If an author says that an analysis is sound, this merely means that the assumptions are stated. It says nothing about the goodness or badness of the analysis with regards to finding bugs. This is what empirical evaluations are supposed to demonstrate.
Furthermore, I think there is room for the development of both sound and unsound analyses in academia. Sound analyses will often focus on pushing the theoretical boundaries of what program analysis can be automated whereas unsound analyses will often focus on finding flaws in large and varied programs. Both provide value and further the development of the field.
Agreed!
Another notable wrinkle to this discussion that I’ve encountered is that [commercial] tool vendors often frame the problem from the other direction: they are writing bug finders rather than program verifiers.
The property they are proving is “The program has a bug”. This effectively inverts the definition of sound and complete, a sound bug finder never reports a false bug and a complete bug finder finds all bugs.
Yes, that’s a good point. Their use of the word “sound” is a source of confusion. In the terminology of this article, the property proved by the tool would be “this program has a bug” (rather than “it has no bug”) and proof would be that the tool emits an alarm (rather than remaining silent). A complete bug finder would say “this program is buggy” for all programs that indeed have one (and some that don’t).
Good post, but it contains a common mistake in understanding Gödel’s incompleteness theorem. For example, first-order logic, a undeniably interesting proof system (and arguably _the most_ interesting one), was proven sound and complete by none other than Gödel, in one of the most important theorems of all of logic, Gödel’s completeness theorem. Even in FOL there are unproveable statements — those will be sentences that are true in some interpretations and false in others.
Thanks for this clarification. I’m not following your last statement: “Even in FOL there are unprovable statements.” This is the point I was making, but I guess I cited the wrong thing? I.e., in reasonable models of programming language semantics (that actually say what the program does, in real implementations), a static analysis cannot be sound and complete. What do you think is the right justification for this? (Note that the Astree homepage centers the issue on decidability, http://www.astree.ens.fr/)
Yes, the issue is decidability (i.e., Rice’s theorem), but completeness and soundness here simply means (precise) “decision”, and not quite what they mean in the context of formal systems (logics). So decision procedures on programs cannot be sound and complete in the sense of neither having false positives nor false negatives.
Gödel’s incompleteness theorem is also a direct result of the halting theorem, but it doesn’t state that any logic cannot be both sound and complete, but that in (rich enough) formal systems, there are statements that are neither provable nor disprovable (which, in the case of FOL, means that there are statements that are neither necessarily true or false).
Thanks a lot for this article, it makes very good points.
There was a “Soundness” discussion in a recent Shonan seminar, and I proposed the following definition for Soundness, in the case of a static analysis tool that aims at over-approximating the behaviors of programs:
Assumptions:
– Lang is the language to analyze and Lang’ a subset of the programs in Lang;
– Exec is a set of all possible executions, and Exec’ is a subset of Exec
– Analysis is a static analysis tool that inputs a program and computes an element of some abstract domain D, with a concretization function gamma: D -> P( Exec ).
Then soundness of Analysis, relatively to Lang’,Exec’ writes down as follows:
forall Program P in a language Lang,
P in Lang’ =>
forall execution t of P,
t in Exec’ =>
t in gamma( Analysis( P ) )
That definition introduces two levels of assumptions:
– Lang’ is a subset of the programs in Lang, that does not retain
programs using features not supported by Analysis (e.g., often,
reflection in Java, or setjump/longjump in C);
– Exec’ is a subset of the executions traces, that does not retain
executions for which it is very hard to say something, typically
because of succession of undefined behaviors.
Those two assumptions are very important. As you explain, it is very common practice to support only a subset Lang’ of the target language, and to achieve soundness under the assumption that the analyzed program does not use unsupported features. I think the Exec’ component is very important too, for several reasons.
One reason is that it is often *very* hard to say something meaningful about all executions of a program, when the semantics leaves behaviors undefined. An example is what happens when a C program breaks memory safety. Then a simple write operation “*p=e;” may cause the program to crash (then the execution stops —simple to capture in the analysis results…), or the program may have all sorts of undefined behaviors, including writing over another memory location, corrupting the code, etc. So, if we consider a static analysis that aims at discovering all possible runtime errors and undefined behaviors, it is very hard to define a sound and precise analysis state after the operation “*p=e;” is reported unsafe. A good solution is to let the analysis emit an alarm at this point, with a clearly specified analysis semantics that the executions for which “*p=e;” writes to an unspecified location are CUT, and that the analysis continues only with correct executions. Astrée will actually do it in this case. It is perfectly fine with respect to the above definition of soundness, since executions with writes to undefined locations will simply not appear in Exec’.
For instance, let us consider:
y = 0;
t[-1] = 1;
x = y;
A real execution may crash or simply write 1 in the location right before the memory space of t, so if this location is y, “x = y” could actually store 1 into x; accounting for all what may happen after an undefined behavior like this is extremely hard to define, and not very relevant to users (whould should mind only of fixing the array access here…), so Astrée will issue an alarm related to the array access, and cut the trace.
It is also convenient to let the analysis soundly cut traces in other cases: for instance, it would be really hard to account for all traces after a function call of the form “*f()” where “*f” cannot be resolved precisely.
Another reason is that users themselves often want to consider a specific sub-set of the program execution traces. For instance this happens in the following cases:
– when specifying assumptions on the program environment (e.g., that some input variable will always be in some well specified range);
– when specifying important properties of the compiler or target running environment, that refine the general language semantics (e.g., the C semantics does not assume the memory is initialized, but some tool chains and loaders will start a program after a set of global locations are initialized to zero).
To conclude, I think that understanding the assumptions of the soundness statement is very important for end-users, to identify (1) the assumptions they need to supply to the tool, and (2) to exactly know what the results of the analysis mean.
Totally agree with all of this, which makes “soundness with assumptions” more precise and actionable. Thanks for sharing the discussion!
Typo:
“all programs not in the circle (including p2-p6) are not proven by A.” should be … (including p3-p6)
Good catch; I’ve fixed this.
The post is well-written and I particularly applaud the explanation of soundness as the standard property from Math, with the analysis as the “proof system” and the program as the “model”. There are so many people that fail to grasp this and consider “soundness” a vague synonym of “correctness, but with a proof”.
However, I have some objections to parts of the main text and the responses. I’ll briefly state the two main ones for future reference:
-“Soundiness” is mischaracterized. Of course, if one defines it as in the post, it is exactly equivalent to “sound up to certain assumptions”. But soundiness refers to something more specific: A soundy algorithm is one that analyzes soundly standard control-flow, calls, parameter passing, heap LOAD and STORE instructions–basically *everything* that we know about from a compiler IR or a core language calculus. Soundy algorithms are *only* unsound relative to a well-identified set of highly dynamic language features: reflection, dynamic loading, etc.
Example: an analysis that does not overapproximate heap LOAD-STORE instructions, is *not* soundy, it is merely unsound! (Ok, “sound under assumptions”, if you want to get pedantic.)
Basically, “soundy” is not a term to throw around lightly. A soundy analysis is trying hard to be sound, and giving up only for the features that virtually all other analyses also give up on. Many published analyses are just unsound, not soundy.
-Xavier offered his part of the Shonan seminar discussion. I’ll offer mine. His definition is a good starting point:
=====================
Then soundness of Analysis, relatively to Lang’,Exec’ writes down as follows:
forall Program P in a language Lang, P in Lang’ =>
forall execution t of P, t in Exec’ =>
t in gamma( Analysis( P ) )
=====================
The problem is that the sets Lang’ and Exec’ in practice contain approximately 0% of realistic programs. (Within standard 2% error rates. :-))
Some people see no problem with that: “The analysis is sound! It has a soundness theorem! Of course, it’s ‘sound under assumptions’. The only issue is to define the sets Lang’ and Exec’ that the analysis is sound for.”
I strongly object to this view. The analysis is *unsound* for virtually all practical programs, if Lang’ and/or Exec’ do not cover the features and executions of these programs. One should not call “sound” an analysis that is sound under assumptions that exclude 99% of real programs, theorem or no theorem. Sorry, but calling a 99% failure a “qualified success” or “success under assumptions” is not good science. Obscuring or ignoring the magnitude of these numbers is either self-delusion or borderline dishonesty.
To me, the challenge of static analysis is not just to dot the ‘i’s and cross the ‘t’s, i.e., to prove a theorem under near-empty-domain assumptions. It is to invent analyses that supports realistically large Lang’ and Exec’ sets, so that the analysis is truly sound for a large subset of realistic program executions.
In the Shonan meeting I tried to offer a vision for how a higher bar of soundness can be achieved: Make the analysis compute standard results (Analysis(P)) together with soundness marker sets (Claim(P)). Then change the typical form of a soundness theorem to be (in Xavier’s notation):
=====================
forall Program P in a language Lang,
forall execution t of P,
t[Claim(P)] in gamma(Analysis(P))[Claim(P)]
=====================
(Where t[Claim(P)] is the restriction of execution t to program points with soundness claims, and the restriction syntax is similarly lifted to sets of executions.)
In other words, the analysis should tell us for which parts of the program (e.g., for which instructions, or for which variables, or for which calls, or …) it claims that its results fully cover any dynamic behavior. There are no qualifications or assumptions on the language features used by the analyzed program, or on its executions.
The advantages of such a soundness theorem are that:
a) we have an analysis that applies to all programs, under all conditions, no matter how weird the features used by the program.
b) the analysis is forced to compute (as one of its outputs) the extent of its soundness. The size of Claim(P) can be measured experimentally. So we can tell for which percentage of a program the analysis is guaranteed to produce sound results.
Interestingly, the above form of the soundness theorem forces very different analysis specifications than past work! If you take a typical current (unsound or soundy) analysis and try to just have it produce a Claim(P) certification of its own soundness, you’ll only be able to prove the theorem for extremely weak Claim(P)s, i.e., it will experimentally fare very badly.
But (I claim) one can design analyses that produce realistically high Claim(P)s. In this way, we can go from current analyses that are sound for, say, 0.5% of Java programs “out there” to analyses that are sound for 100% of them, but only “certify” their results for, on average, the 30-40% of the program text that is certain to be unaffected by highly-dynamic features.
Pingback: 프로그램 분석에서의 Soundness – Bloofer Blog
Great article – I find myself having to explain these terms to customers all the time, so it’s good to have a definitive source that supports the way we teach this stuff. I also recall reading Ben Livshits’ “Soundy” article and really wishing that we’d invented the term a long time ago – it would have helped to explain things. Another example, by the way, of a consciously “soundy by design” language is SPARK (The Ada subset, not the Apache thing). SPARK strongly enforces its assumptions through language subsetting and mandatory initial analyses, so that the subsequent Hoare-logic VCG and proving really does work. The main problem, of course, is that it’s almost impossible to apply retrospectively to any kinda legacy code-base. Coverity made the case well in their “Billion lines of code…” article – in short, to sell lots of tools to lots of people, you need to be able to analyse the worst undefined and unspecified crap ever written in all unsubsetted languages… which means soundness is the first thing to go out the window.. ah well…
Thank you for this post. Soundness is so often mentioned in static analysis publications that I have always thought it was important to make its meaning crystal clear – and also to discuss the inherent limitations of using just soundness as a criterion. Fritz Henglein gave a talk about just that in 2013, which he said went back to a Shonan workshop – I don’t know if it’s the same that Xavier and Yannis mentioned – but here it is: http://dansas.sdu.dk/2013/slides/Henglein-soundness.pdf .
To me an important point is that Rice’s theorem and similar undecidability results are often stated as a justification to avoiding any discussion of precise decision procedures (sound & complete). However, basically any algorithm that attempts to decide a program property, if there is any sense in it, is based on (sometimes concealed) subset of language features that the algorithm focuses on, while ignoring others. This can be made explicit by defining a weak language which is your stated goal and, being weak, the undecidability results do not apply. So sound & complete for a weak language is an achievable goal, and has the benefit of giving a precise formulation of what has been achieved in a logical sense. In my experience, having a well-defined goal such as completeness for a weak language does a lot to push research forward. Moreover, in the context of verifying desirable program behaviours, a completeness proof (even for a weak
language) has a useful bi-product: it usually shows how to justify a negative result. That is, if the analyser fails to prove some safety property, say, the completeness proof helps to generate a failing run, which is useful in understanding the cause of the alarm, sometimes detecting and avoiding false alarms, etc.
I would like to echo Arlen Cox’s conclusion that research should try both to improve the practical success of tools (empirics are a must here) and to push the boundaries of what we know how to solve (based on the logical criterion of soundness). But for the latter, I propose to think not just of soundness, but also of completeness for well-defined relaxed problems. The relaxed problem may be defined by a weak language, or perhaps by Lang’ and Exec’ as in Xavier’s comment. I also think that Yannis’s proposal may be well served by this mode of thinking.
Very complete and precise post. It helped me a lot to fully understand the topic.
Maybe the sentence: “A static analysis generally says a program P enjoys a property like R by emitting no alarms when analyzing P.” could be rephrased in a different way [or removed].
And I don’t know a shorter version than this the one below 🙂
Remodeling the sentence:
For Sound (SA) Tools, no alarms emission regarding a property R in a given program P means the presence of R in P (or that P enjoys R, as written in the post).
For Complete (SA) Tools, no alarms emission regarding a property R in a given program P does not mean that P enjoys R. So a Complete tool may accept the absence of R, therefore no alarms.
Let R be “safe software” for clear understanding.
Therefore, *no alarms emission* for the property R in a given program P means,
For sound tools: R *is* present in P. – safe software!
For complete tools: They can’t guarantee the present of R in P. P can still be unsafe. (false negative)
If *alarms are raised* then:
For sound tools: The alarm can be wrong since P can enjoy R. (false positive)
For complete tools: R *is not* present in P. – unsafe software!
I’m curious to know why you think it’s important to have more benchmarks to compare static analyses? First, there are language specific benchmarks used to compare static analyses, for example the SATE benchmarks for C or Java (https://samate.nist.gov/SATE.html). The problem is legal, they cannot disclose the results they get with proprietary static analyzers! So they resort to publishing anonymized summaries.
Secondly, I would not trust any benchmark to select a static analyzer. Much better to just run them all on your software (your current software is very representative in general of what you’ll write/have tomorrow) and choose based on this very concrete data.
Thirdly, I think it risks being a waste of time for academic tools to deal with such “representative/realistic” benchmarks, as you may end up spending an awful lot of time to deal with the zillion situations that your tool does not deal with gracefully, instead of focusing your efforts on the one contribution you’re making to the community. Working myself on industrial static analyzers, I don’t expect such validation in academic work, and I’m very suspicious in general of “realistic” experimental validation in that context.
FWIW, the community around deductive verification tools organized a Dagstuhl seminar in 2014 around this topic of benchmarks and competitions: https://www.dagstuhl.de/en/program/calendar/semhp/?semnr=14171 You may contact one of the organisers to see what the seminar brought and how the situation has evolved in this community.
Unrelated to the above, here is a recent article from colleagues on the difference between sound and unsound static analyses, targeted as software engineers: https://www.electronicdesign.com/embedded-revolution/whats-difference-between-sound-and-unsound-static-analysis
Thanks for the comments! I see where you are coming from in worrying about dragging down idea-exploration in academic work with grungy details and standards. However, I am not persuaded that we are better off without a good benchmark. Quick responses to your points:
1) My students looked at the SAMATE benchmarks at several points in time and did not find them very useful. Maybe we were looking in the wrong place. In many cases the buggy program fragments would fail deterministically if you just ran them. I.e., not very representative. By contrast, the Da Capo benchmark suite, or SPEC, involves real programs that are germane to various sorts of language tools. I don’t know why benchmarks like these might be needed in general, but not for static analysis. In particular, if I am a researcher reading a paper, I would like to know: Does this technique actually work, or does it sound good? There is often too much of the latter. And you only find that out when you waste a lot of time implementing what’s in the paper, and you find it doesn’t work as well as the paper makes it seem to. It will be harder to do that when standard, good, useful benchmarks are at play.
2) Not an option for research papers, where the techniques are not released as code, or even if they are, “running it on all your programs” is not always so easy.
3) Fair enough. But I would be surprised if we could not overcome this situation. Again, Da Capo and SPEC somehow don’t create an insurmountable barrier for the many tools that use them.
Thanks again for sharing your perspective!
Thanks for your answer. I also see your point now. IIUC your main objective is to facilitate the evaluation of research ideas/prototypes. Then I think we’re not short of benchmark suites, if you consider all the code on GitHub (or for even more code http://www.softwareheritage.org). At least that gives you generalizability if you select representative actual software. To get at least some degree of ground truth as you said, it would be possible to look at the National Vulnerability Database (like these NIST researchers did https://ws680.nist.gov/publication/get_pdf.cfm?pub_id=925468) to select a past snapshot containing enough interesting vulnerabilities? Maybe that’s even something NIST (Paul Black) could be interesting in doing, as they keep evolving the SAMATE testsuites?
Yes, indeed, Github is a great source of programs on which to evaluate static analysis. But without an independent identification of which of those programs to use, researchers are free to choose ones that suit their tool (“cherry pick” them). As you say, one must “select representative, actual software.” SPEC and Da Capo are useful because an independent body has selected them to be real and representative; authors will feel inclined to justify why they are leaving out particular programs in the suite, or simply not using it. My co-authored paper at ESOP’18 was originally rejected for only considering a subset of the Da Capo programs. We improved our tool and adjusted our approach so that we could use them all, and I must say the work was much better for it. As for ground truth: I agree that drawing bugs from real sources (e.g., past program versions with known bugs in them) would be ideal. None of this is easy, which is part of why people don’t do it, I’d guess. But it can be very important for advancing science!
In case you have not seen it before, the paper “Towards Automatically Generating a Sound and Complete Dataset for Evaluating Static Analysis Tools” (https://ruoyuwang.me/bar2019/pdfs/bar2019-final90.pdf) defines a neat way to create such benchmarks automatically. The paper talks only about static analysis for binaries, but there is no reason it would not work on source code.
This excellent article is very enlightening. It occurred to me that that there is both more to be said (emphasizing duality of soundness and precision) and less (providing a simpler presentation) and expressed it in a new article: https://bertrandmeyer.com/2019/04/21/soundness-completeness-precision/.
Pingback: New top story on Hacker News: What is soundness in static analysis? (2017) – Golden News
Pingback: New top story on Hacker News: What is soundness in static analysis? (2017) – protipsss
Pingback: New top story on Hacker News: What is soundness in static analysis? (2017) – World Best News
Pingback: New top story on Hacker News: What is soundness in static analysis? (2017) – Hckr News
Pingback: New top story on Hacker News: What is soundness in static analysis? (2017) – Latest news
Pingback: New top story on Hacker News: What is soundness in static analysis? (2017) – News about world
Pingback: New top story on Hacker News: What is soundness in static analysis? (2017) – Outside The Know
Pingback: What is soundness in static analysis? (2017) – INDIA NEWS
Pingback: What is soundness in static analysis? (2017) – Boston Area Casino News